Améliorer ses requêtes Mongo avec Atlas et .explain()
Quoi de plus frustrant qu’un site qui rame ? Rien. Si à chaque clic l’utilisateur·rice doit patienter en cherchant des formes dans les nuages pour faire passer le temps, pas sûr que grand monde reste sur votre site …
Quoi de plus frustrant qu’un site qui rame ? Rien. Si à chaque clic l’utilisateur·rice doit patienter en cherchant des formes dans les nuages pour faire passer le temps, pas sûr que grand monde reste sur votre site …
Allez, on a (sûrement) du boulot !
Identifier les problèmes avec Atlas
MongoDB Atlas est un service de base de données dans le cloud, créé par la même entreprise que MongoDb. C’est un outil qui permet, entre autres, de monitorer l’état de la base de données.
Metrics
Les deux graphiques qui nous intéressent ici sont “Query Executor” et “Query Targeting”, que l’on trouvera dans l’onglet “Metrics”. Ils nous donneront une idée de la réponse à “y-a-t’il des choses à améliorer ?” mais ne nous donneront pas de précision sur quoi exactement. Cependant, ils sont un bon indicateur de l’état général de nos queries.
Query Executor
Sur ce graphique, on pourra voir :
- en bleu le nombre moyen d’index scannés;
- en vert le nombre moyen de documents scannés;
données correspondantes à respectivement totalDocsExamined et totalKeysExamined que l’on
retrouve en sortie d’un explain().
Plus la courbe verte est éloignée de la courbe bleue, moins les index sont utilisés dans les
requêtes de l’application, ce qu’on cherche à éviter.
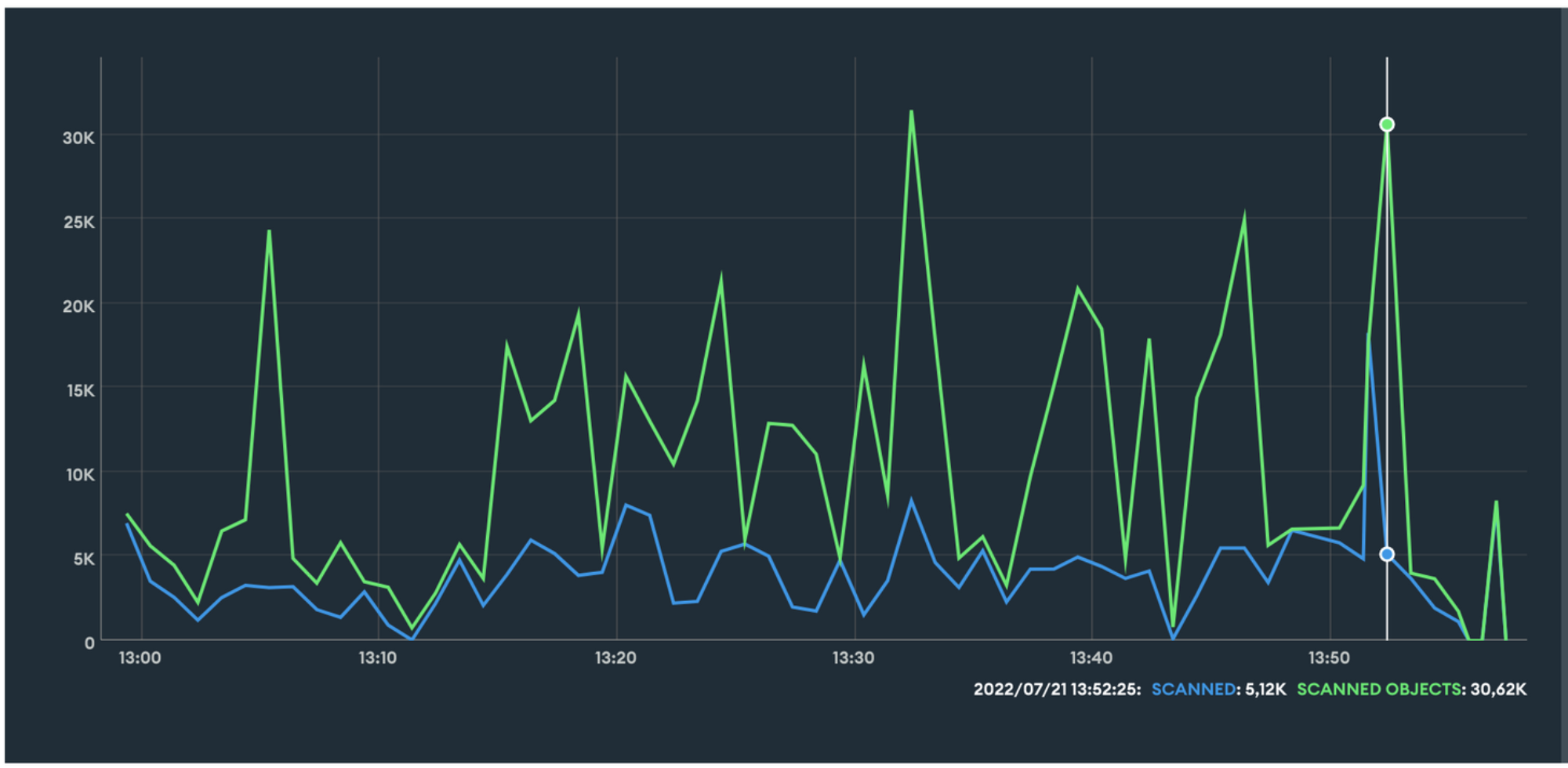
“scanned” : The average rate per second over the selected sample period of index items scanned during queries and query-plan evaluation. This rate is driven by the same value as totalKeysExamined in the output of explain(). ”
scanned objects” : The average rate per second over the selected sample period of documents scanned during queries and query-plan evaluation. This rate is driven by the same value as totalDocsExamined in the output of explain().
Query Targeting
Ce graphique représentant des ratios est peut-être plus intéressant à regarder pour déterminer si l’on a besoin de travailler sur nos queries. Un ratio de 1 indique que le nombre de documents ou d’index scannés est égal au nombre de documents renvoyés. On cherchera donc à se rapprocher de cette valeur, ce qui n’est pas toujours facile. Par exemple, on en est loin ici :
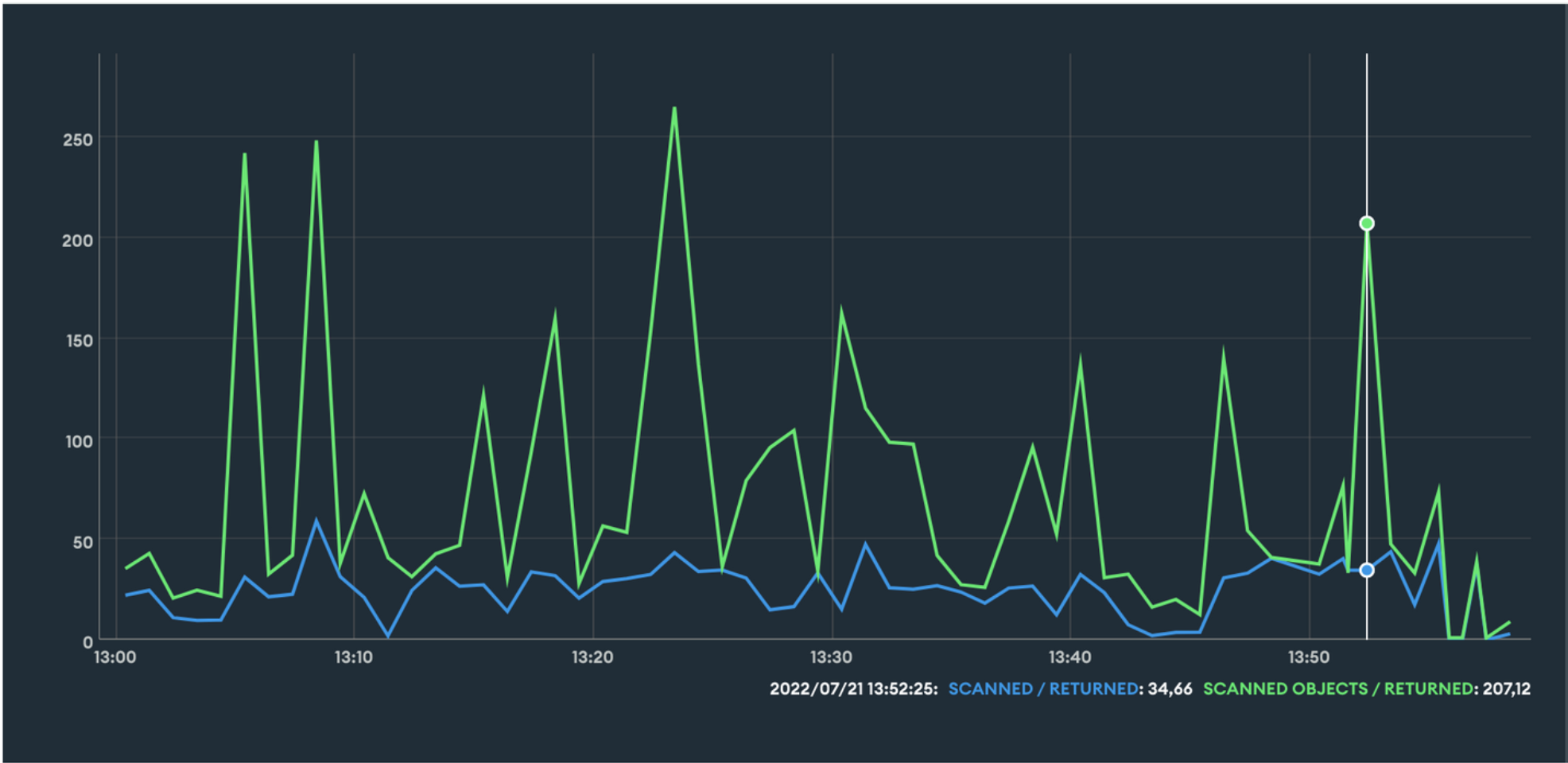
“scanned / returned” : The ratio of the number of index items scanned to the number of documents returned by queries, since the previous data point for the selected sample period. A value of 1.0 means all documents returned exactly match query criteria for the sample period. A value of 100 means on average for the sample period, a query scans 100 documents to find one that's returned.
”scanned objects / returned” : The ratio of the number of documents scanned to the number of documents returned by queries, since the previous data point for the selected sample period.
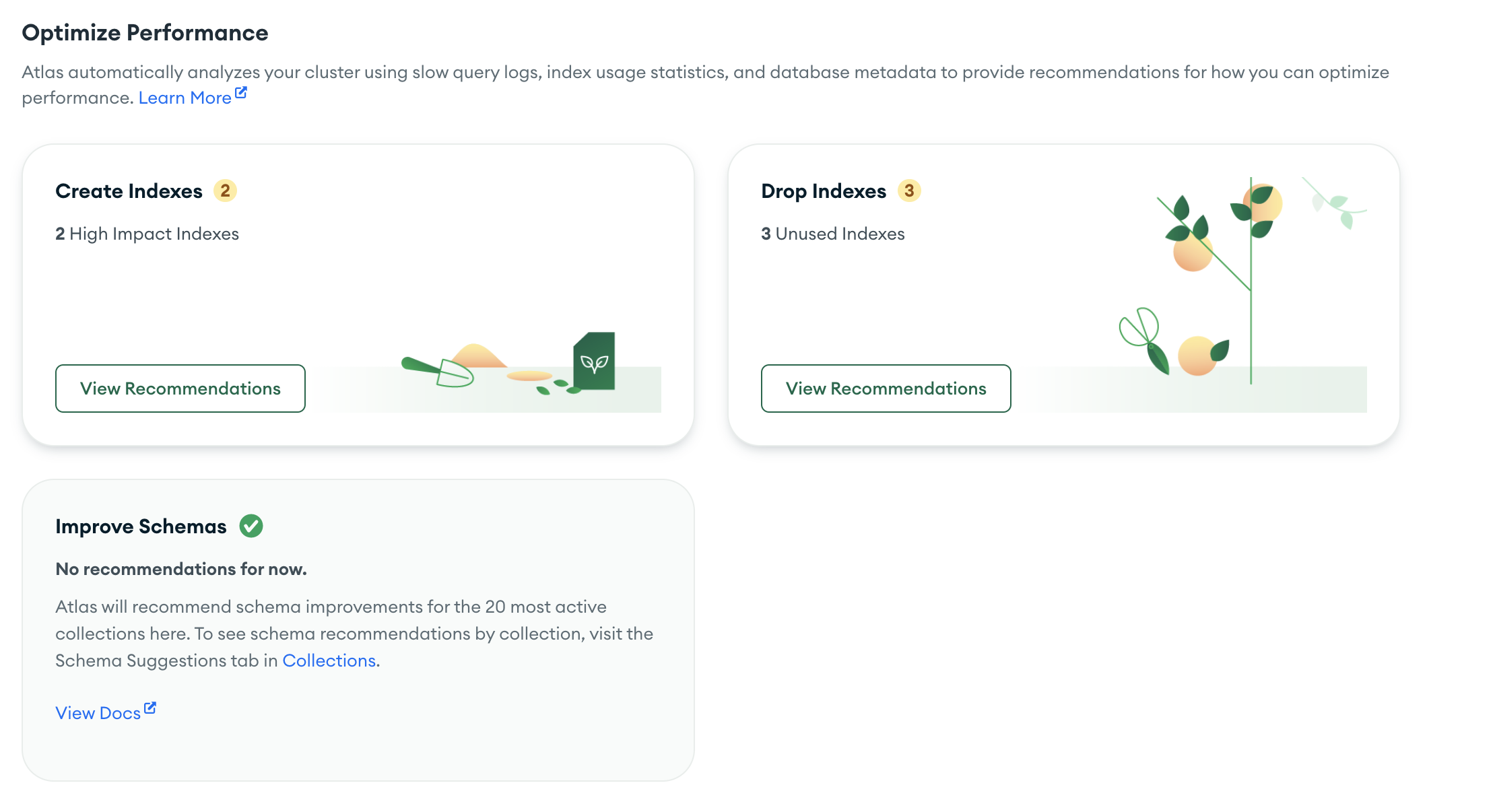
Performance advisor
Cet onglet peut proposer des créations ou suppressions d’index en fonction de nos queries. Même s’il est tentant de cliquer sans trop regarder, il vaut mieux réfléchir un peu avant. En effet, ajouter des indexes sur un peu tous les champs serait contre-productif : Mongo pourrait utiliser un index plutôt qu’un autre sans que ce soit forcément le bon choix. Autre potentiel problème : si les indexes créés sont triés et stockés dans la RAM, il faut s’assurer qu’on ne dépasse pas la place allouée !
Ces propositions d’indexes se basent sur les requêtes faites sur l’app, et si elles ne sont pas écrites en pensant un minimum perf, les indexes proposés ici ne seront pas forcément pertinents.
Profiler
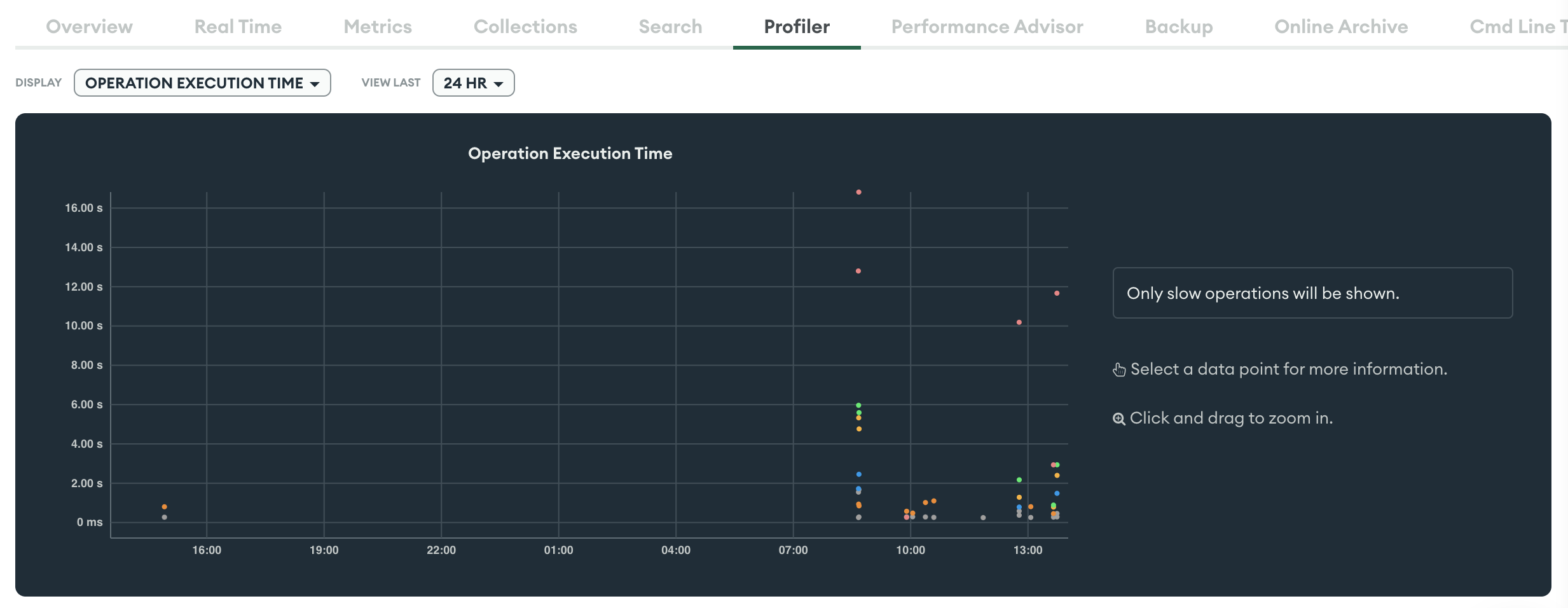
C’est sur cet onglet qu’on va enfin pouvoir mettre les mains dans le cambouis. Ce graphique identifie les requêtes “trop longues” selon Atlas.
En cliquant sur un point du graphique, le détail de la requête incriminée apparait.
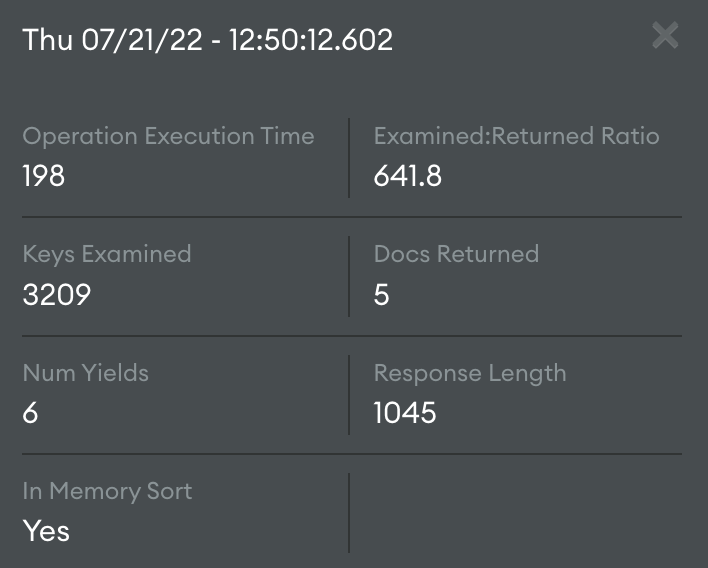
Sur cette requête, le nombre documents examinés via l’index est de 3 209 alors qu’on ne renvoie au final que 5 documents !
On trouvera également le détail de la requête, ce qui nous permettra d’identifier exactement dans quelle partie du code elle se trouve.
{
"type": "command",
"command": {
"aggregate": "myCollection",
"pipeline": [],
…
},
"planSummary": "IXSCAN { someField: 1 }",
"keysExamined": 3209,
"docsExamined": 3209,
"hasSortStage": true,
"cursorExhausted": true,
"numYields": 6,
"nreturned": 5,
"durationMillis": 198,
…
}
Attention, toutes les requêtes à la base de données sont affichées ici ! De ce fait, si vous faites des requêtes un peu gourmandes à la mano dans votre terminal, elles apparaîtront aussi ici.
Maintenant qu’on a identifié une requête qui pose problème, c’est cool, mais on fait quoi ?
Améliorer ses requêtes
Lire et comprendre un .explain()
La doc Mongo est par ici et là.
TL;DR, on peut (essayer de) comprendre ce que fait Mongo avec notre requête, en faisant :
db.getCollection('myCollection').find({ ... }).explain('executionStats');
Attention, pour les aggregate, c’est dans l’autre sens ! Le .explain() vient avant le
.aggregate(). Pour la lecture, c’est le même principe.
db.getCollection('myCollection').explain('executionStats').aggregate([ ... ]);
Pour le .find(), on aura un résultat du style :
{
"queryPlanner" : {
"parsedQuery" : {...},
"winningPlan" : { -- plan utilisé
"stage" : "FETCH",
"filter" : {...},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"myFieldWithIndex" : 1
},
"indexName" : "myIndexName",
"isMultiKey" : false,
"isUnique" : false,
...
}
},
"rejectedPlans" : [],
...
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 32199, -- nombre de documents renvoyés
"executionTimeMillis" : 160, -- temps d'exécution
"totalKeysExamined" : 49805, -- nombre d'indexes examinés
"totalDocsExamined" : 49805, -- nombre de documents examinés
...
},
...
}
On peut déjà comparer le executionStats.nReturned et executionStats.totalDocsExamined. Si on a
la même valeur, cela veut dire que tous les documents parcourus sont renvoyés en réponse.
Est-ce qu’un index a été utilisé ? On peut voir ça à plusieurs endroits :
executionStats.totalKeysExaminedqui nous donne le nombre de documents examinés via un indexwinningPlan.inputStage.stagequi vautIXSCAN(voir ci-dessous)winningPlan.inputStage.indexNamequi nous donne le nom de l’index utilisé
Le champ stage peut prendre plusieurs valeurs :
COLLSCANquand toute la collection est scannée (en général, on va essayer de ne pas avoir cette valeur dans le premier stage au moins)IXSCANquand on examine les documents via un indexFETCHquand on récupère des documentsGROUPquand on groupe des documentsSHARD_MERGEpour fusionner les résultats des shardsSHARDING_FILTERpour filtrer les documents orphelins des shards
Pour diminuer le temps d’exécution, le but va être d’avoir le moins possible de COLLSCAN au profit
des IXSCAN.
Exemple
Imaginons une collection transactions sans index et avec 106 041 documents de la forme suivante :
{
"_id" : "j9sdaW87Wv5gck443",
"date" : ISODate("2022-09-24T00:00:00.000Z"),
"id_user" : "1234",
"id_bank_account" : "gTdxTA9ZvZrsrML6S",
"description" : "Virement",
"subdivisions" : [
{
"id" : "b44jxF599Tk8qkj32",
"amount_in_cents" : 89400,
"accounting_account" : "471000",
},
{
"id" : "43BRMJHuXYNfxogdD",
"amount_in_cents" : -89400,
"accounting_account" : "512001",
}
]
}
Prenons cette requête qui liste les transactions de l’utilisateur 1234 pour un compte comptable et
une date :
db.getCollection("transactions")
.find({
id_user: "1234",
"subdivisions.accounting_account": "471000",
date: ISODate("2022-09-24 00:00:00.000Z"),
})
.explain("executionStats");
Et l’explication de son résultat :
{
"queryPlanner" : {
...
"winningPlan" : {
"stage" : "COLLSCAN", -- n'utilise pas d'index
...
},
"rejectedPlans" : [] -- n'a pas trouvé d'autre possibilité d'exécution
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 5, -- nombre de documents retournés
"executionTimeMillis" : 62, -- temps de réponse
"totalKeysExamined" : 0, -- n'examine pas d'index
"totalDocsExamined" : 106041, -- nombre de documents examinés
...
},
...
}
Avoir une requête qui n’utilise pas d’index n’est pas un problème en soit. Ce qu’il faut regarder c’est le ratio entre le nombre de document examiné (ici 106 041, c’est à dire toute notre collection !) et le nombre de documents retournés (ici, uniquement 1). Cette collection stocke des transactions bancaire, elle sera amenée à grossir rapidement : on ne peut pas se permettre de scanner toute la collection à chaque fois.
Créons un index sur les dates avec db.getCollection('transactions').createIndex({ "date" : 1 }) .
On aura alors un résultat plus satisfaisant :
{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"indexName": "date_1", -- index utilisé
...
},
},
"rejectedPlans": [] -- n'a pas trouvé d'autre possibilité d'exécution
},
"executionStats": {
"executionSuccess": true,
"nReturned": 5, -- nombre de documents retournés
"executionTimeMillis": 6, -- temps de réponse
"totalKeysExamined": 8, -- nombre d'indexes examinés
"totalDocsExamined": 8, -- nombre de documents examinés
...
},
...
}
Le temps de réponse a grandement diminué, on utilise un index et on examine beaucoup moins de documents.
Mais il est encore possible d’améliorer notre résultat en examinant des indexes à la place des documents.
Supprimons notre index pour en créer un autre :
db.getCollection("transactions").createIndex({
id_user: 1,
"subdivisions.accounting_account": 1,
date: 1,
});
Ce qui nous donne :
{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"indexName": "id_user_1_subdivisions.accounting_account_1_date_1", -- index utilisé
...
},
},
"rejectedPlans": []
},
"executionStats": {
"executionSuccess": true,
"nReturned": 5, -- nombre de documents retournés
"executionTimeMillis": 5, -- temps de réponse
"totalKeysExamined": 45, -- nombre d'indexes examinés
"totalDocsExamined": 5, -- nombre de documents examinés
...
},
...
}
Avec cette index, le nombre de documents examinés est égal au nombre de documents retournés. Le nombre d’indexes examinés a augmenté mais cela n’est pas un problème pour les performances sur cet ordre de grandeur.
Attention toutefois, ici l’exemple ne s’appuie que sur une seule requête. Il est peu probable que vous ayez à faire une seule requête par collection. Il vous faudra alors penser vos index pour qu’ils servent sur la majorité de vos requêtes.
Créer des index dans tous les sens pourra aussi vous desservir : Mongo choisira d’utiliser un des indexes créés, il est possible que ce ne soit pas forcément celui auquel vous pensiez !
Pour visualiser l’utilisation de vos indexes, utilisez
$indexStats :
db.getCollection('transactions').aggregate( [ { $indexStats: { } } ] )
Monitorer
Les graphiques disponibles sur Atlas présentés plus haut nous donnent une idée de l’état de la base à un instant t. Sur Query Executor et Query Targeting il n’est pas possible de différencier les collections. Sur le Profiler, c’est un petit peu plus précis, mais on ne peut remonter que sur les dernières 24h.
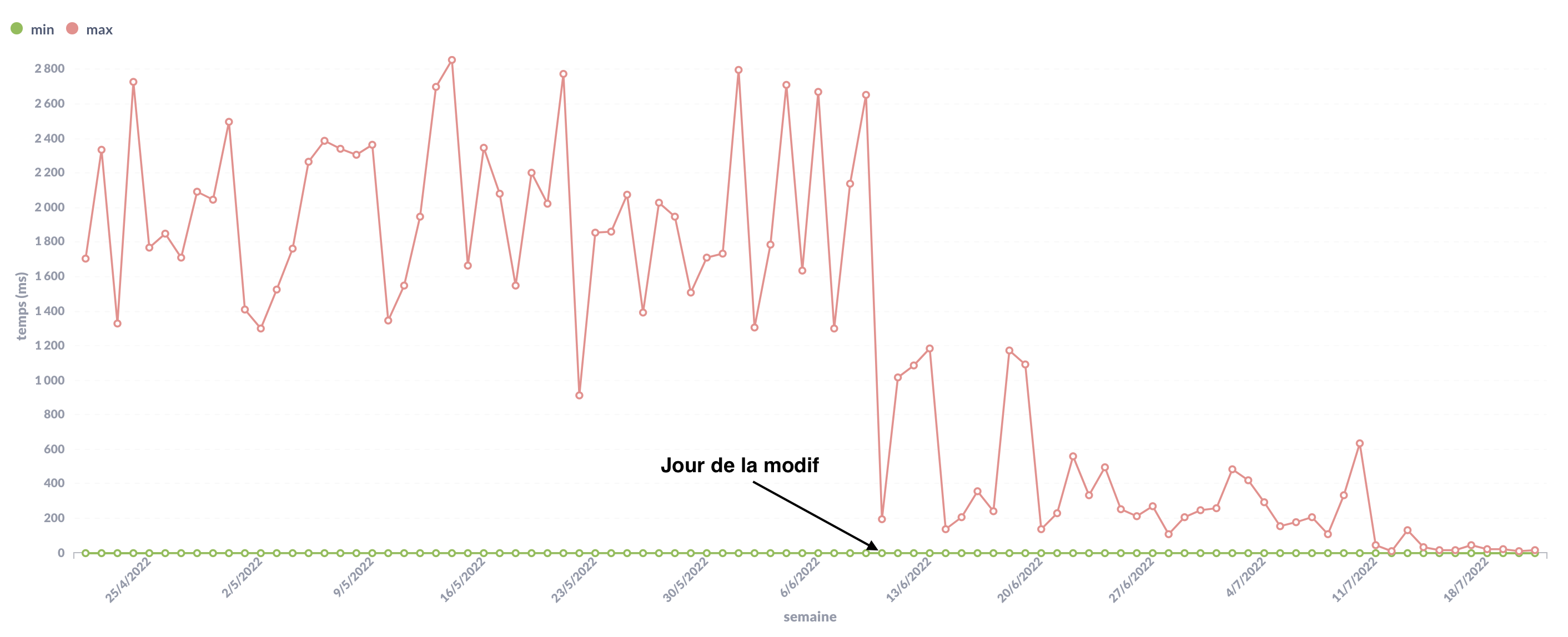
Pour avoir une vue plus globale des évolutions de performance suite aux différentes modifications, il est possible de monitorer les temps de réponse des routes. Certes, on mesurera tout un tas de choses en plus de “l’amélioration de la requête”, mais cela permet de voir si notre feature a besoin de plus de travail (possiblement autre que sur Mongo).
Par exemple, une des requêtes améliorées lors de nos sessions avec la guilde Mongo a été monitorée. Cette route ne fait qu’une requête Mongo et peu de traitements JS, nous étions donc assez confiants sur les impacts positifs de notre travail.
Pour aller plus loin …
- Créer un index B-tree composé efficacehttps://tech.indy.fr/2022/04/07/creer-un-index-b-tree-compose-efficace/
- Let’s .explain() MongoDB Performance | Twitch Live Codinghttps://www.youtube.com/watch?v=HAtnkHw_fJ8
- Mongo Universityhttps://university.mongodb.com/courses/M201/about