Créer un index B-tree composé efficace,
Un défi plein de pièges. Nous avons tous eu à indexer nos bases de données à un moment donné.
Créer un index B-tree composé efficace, un défi plein de pièges

Nous avons tous eu à indexer nos bases de données à un moment donné.
Nous avons tous cherché à indexer plusieurs champs avec des index composés à un moment donné.
Et pourtant nos index composés peuvent avoir fait pire que mieux ou ne pas être à la hauteur. Nous allons ici avec un véritable use case voir la différence entre les bons et les mauvais index composés.
Rappel du B-tree et idées reçues
Etant donné l’étendu de la littérature sur les B-tree, nous ne nous étendrons pas trop dessus. Pour mémoire, le fonctionnement du B-tree est le suivant
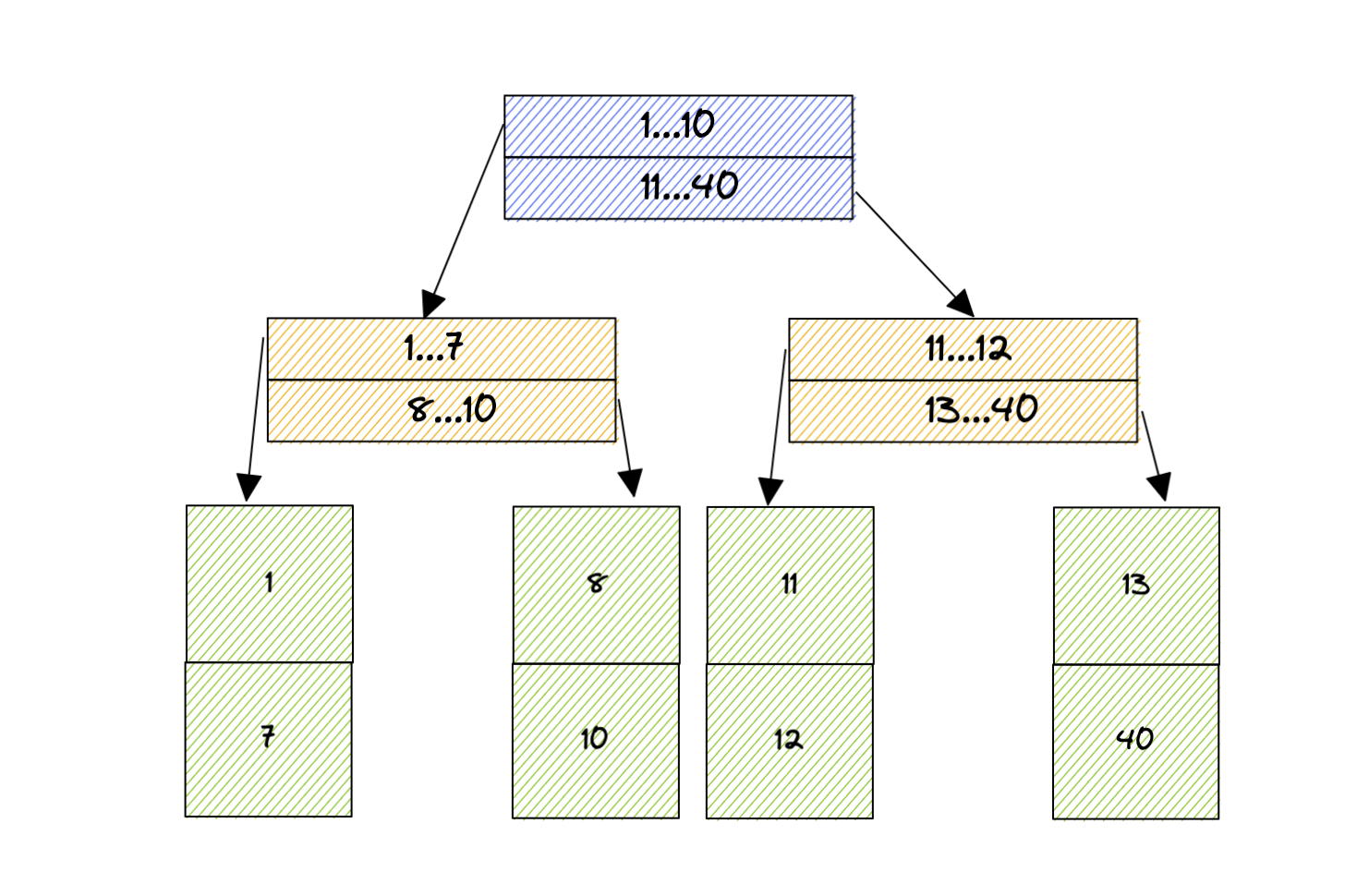
Pour lire la valeur 7, on va traverser l’arbre en partant du nœud racine en bleu, traverser la branche jaune à gauche et lire les valeurs en vert. La, l’index va nous donner directement l’adresse de l’enregistrement voulu.
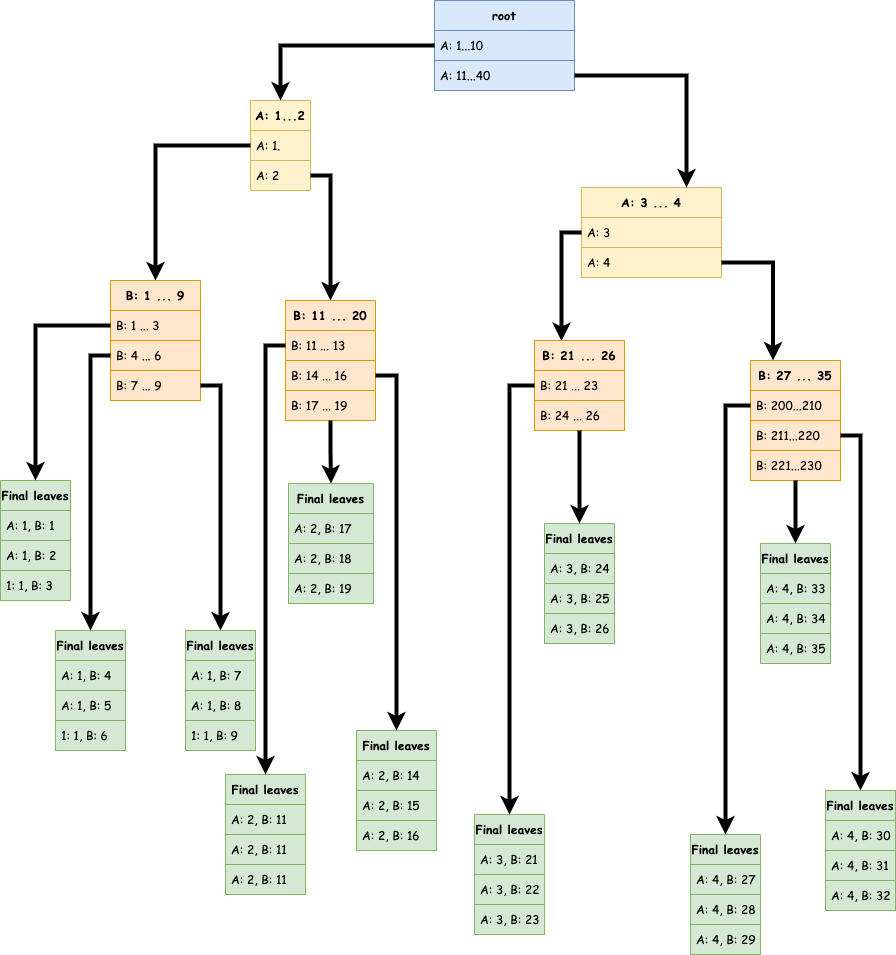
Dans le cas d’un index composé, l’index sera une succession d’index simples.
Exemple de schéma si on créé un index B-tree sur les colonnes “A” et “B” (dans cet ordre).
Par exemple avec la requête SQL
CREATE INDEX "composed_index_name" ON "my_table" ("A", "B");
On va créer l’arbre suivant
Si maintenant, je veux la valeur A: 1, B: 5 voici le parcours (en rouge) qui va être effectué.
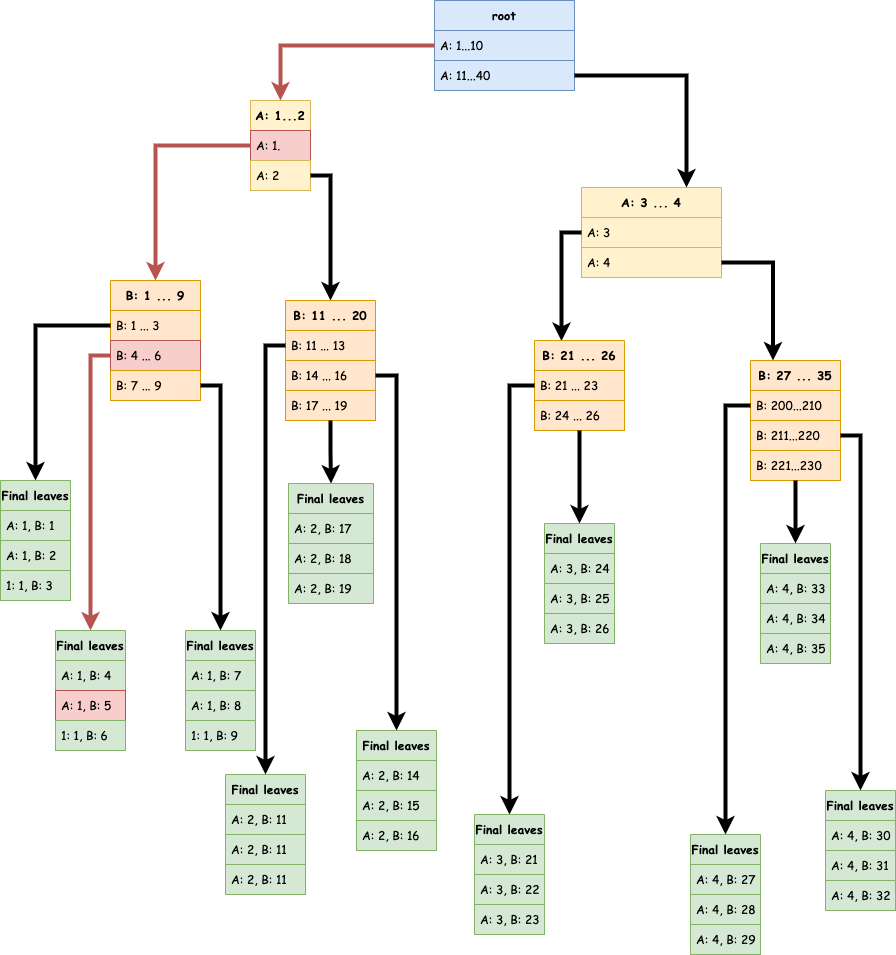
Si on suit le trajet en rouge lors d’une requête : aucun doute c’est vraiment bien optimisé.
De plus, en observant l’arbre, on voit apparaître un pattern assez connu et souvent documenté.
Un index sur A et B permet aussi d’indexer des queries sur A uniquement
Si, je reprend, l’exemple, si je veux tous les enregistrements ayant pour valeur de A à 1 il
suffit de parcourir l’arbre en rouge ci-dessous.
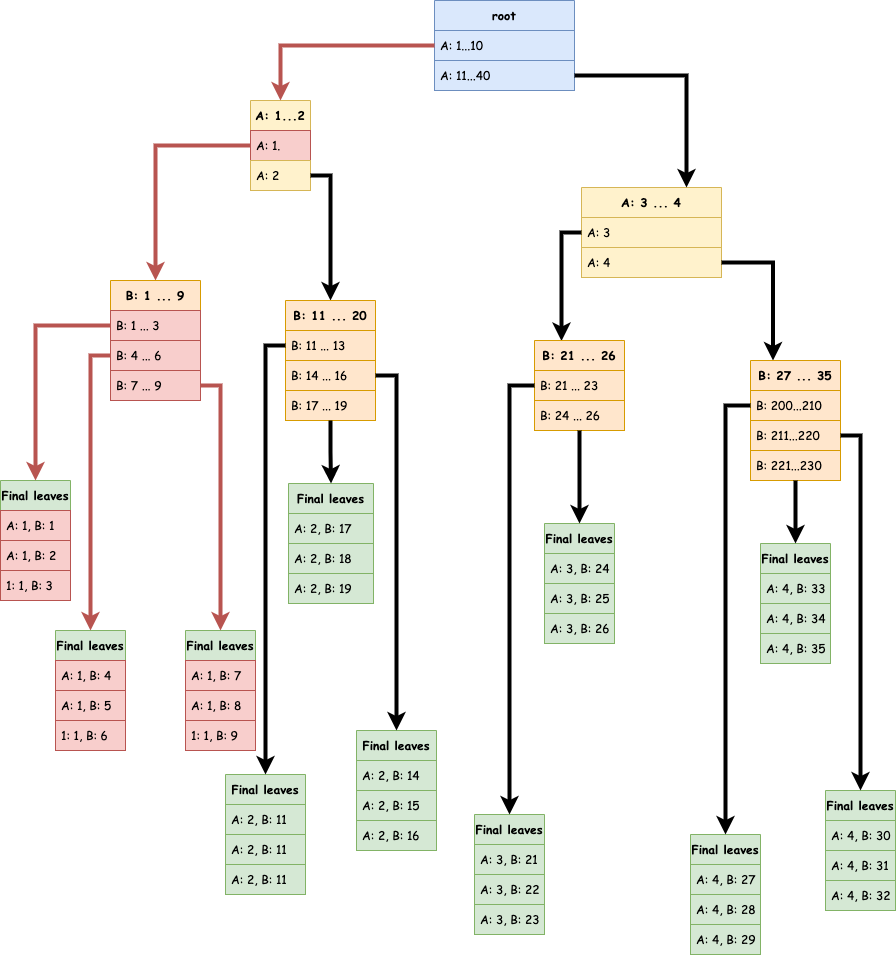
Relativement peu de flèches rouges, ça semble être effectivement une bonne astuce à première vue.
Le piège du composed index
Nous allons maintenant nous intéresser à l’index composé et essayer de voir comment il peut devenir un piège.
Les données théoriques de nos index
Pour ce faire, nous allons nous intéresser à de la donnée plus proche de la réalité que notre exemple théorique. On va stocker en base de données des exécutions de tâches s’exécutant trois fois tous les dix jours et échouant une fois sur trois.
Ce qui nous donne les données suivantes :
| date | status |
|---|---|
| 2022-01-01 | success |
| 2022-01-05 | error |
| 2022-01-10 | success |
| 2022-01-11 | success |
| 2022-01-15 | error |
| 2022-01-20 | success |
| 2022-01-21 | success |
| 2022-01-25 | error |
| 2022-01-30 | success |
Si nous avons les deux requêtes suivantes à indexer :
- Récupérer un run pour une date donnée
- Un compte des runs en échec entre deux dates. L’exemple s’appliquerait aussi si nous voulons
tous les runs en échecs (sans compte), mais la récupération des runs serait coûteuse en temps,
le
countnous permet de mesurer uniquement le temps de parcours de l’index en excluant le fetch de données.
# Requête 1
SELECT * from runs WHERE date = <date>
#Requête 2
SELECT count(*) from runs WHERE date > <date_start> AND date < <date_end> AND status = 'error'
Premier index
En bon développeur devant une requête SQL lente, nous allons penser index.

A partir de l’idée reçue vue au paragraphe précédent, nous allons préférer l’index suivant :
CREATE INDEX "date_status" ON "runs" ("date", "status");
Cet index, semble couvrir les deux queries avec un seul index.
Intéressons nous maintenant à l’arbre que cet index va générer.
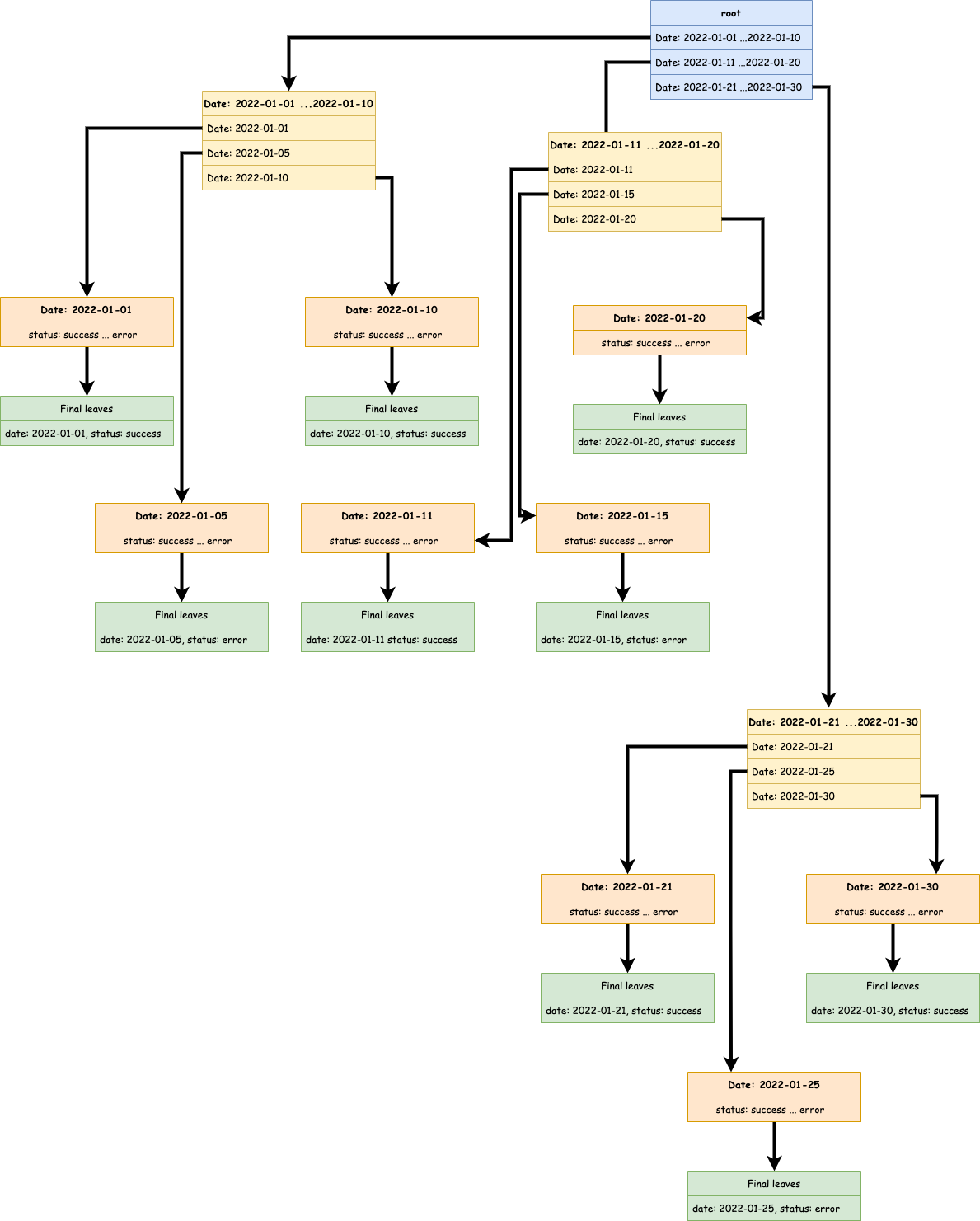
Par rapport à ce à quoi nous nous attendions, celui-ci semble étrange.
En effet, nous n’avons qu’un enregistrement par bloc de feuilles (en vert). Et il y a beaucoup de flèches.
Nous allons maintenant exécuter nos deux requêtes :
Récupérer un run pour une date donnée
Si je veux récupérer le run du 21/01/2022, je vais exécuter le trajet suivant (en rouge).
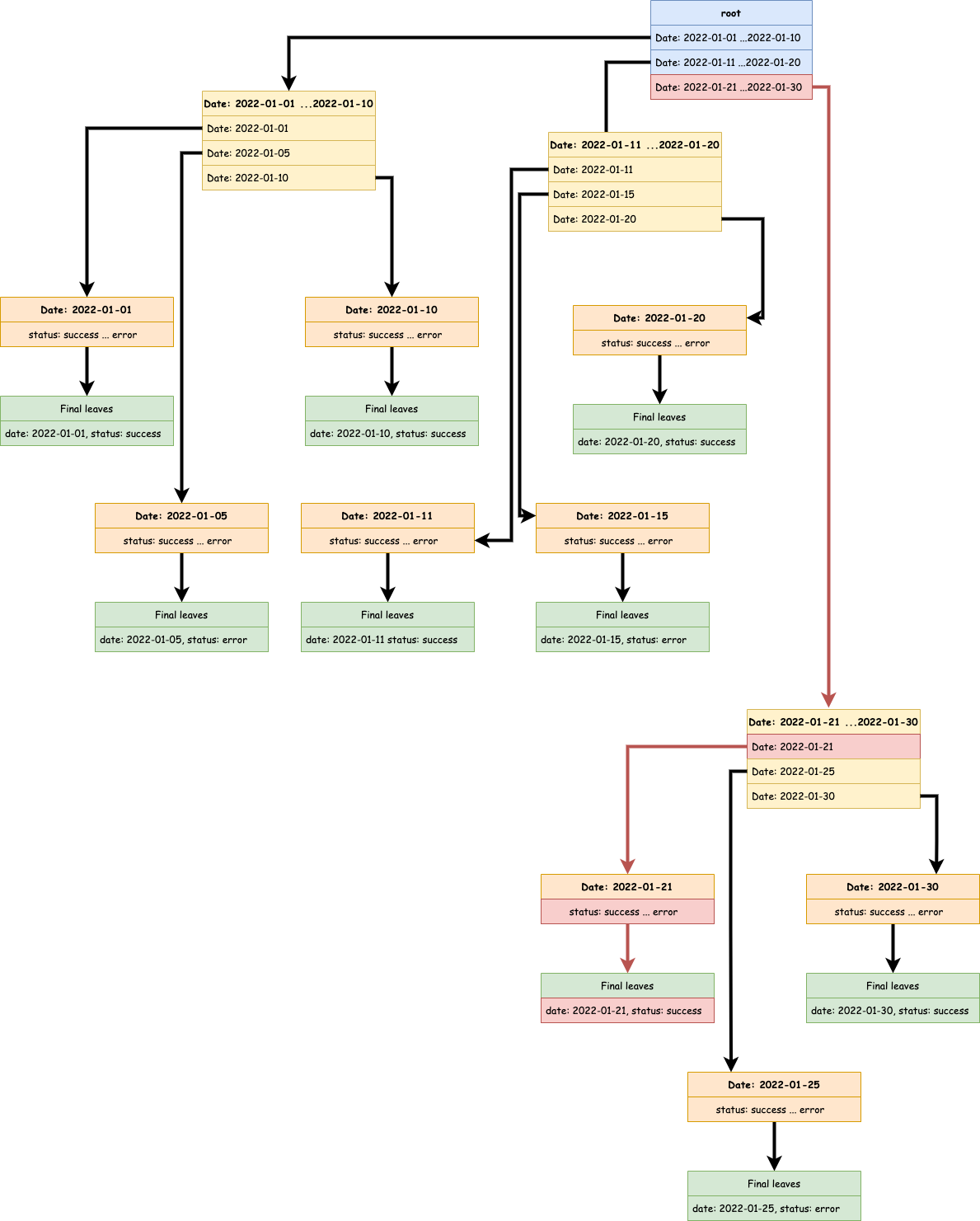
Le trajet semble plutôt bien optimisé. Peu de flèches rouges empruntées. Vérifions ça par la pratique. Nous allons utiliser la base de données témoin contenant 10 millions de runs avec un run sur 100 en erreur.
| Scénario | Temps d’exécution | Taille d’index |
|---|---|---|
| Sans index | +/- 2s | 0Mb |
index date_status | +/- 2ms | 160Mb |
| index date | +/- 2ms | 120Mb |
On remarque que le temps d’exécution est très proche avec l’index date_status qu’avec l’index
date uniquement.
Le contrat est donc clairement rempli avec cet index sur cette requête.
Seul bémol, la taille de l’index est bien supérieure à celle de l’index date uniquement on comprend aisément pourquoi en revenant à l’arbre. La surabondance de blocs et de flèches se paye sur la taille de l’index.
Tous les runs en échec entre deux dates
Les choses vont se compliquer dans ce cas. Dans notre exemple théorique, si je demande une plage de date équivalente à la moitié de l’amplitude de la base, on se retrouve avec le parcours suivant.
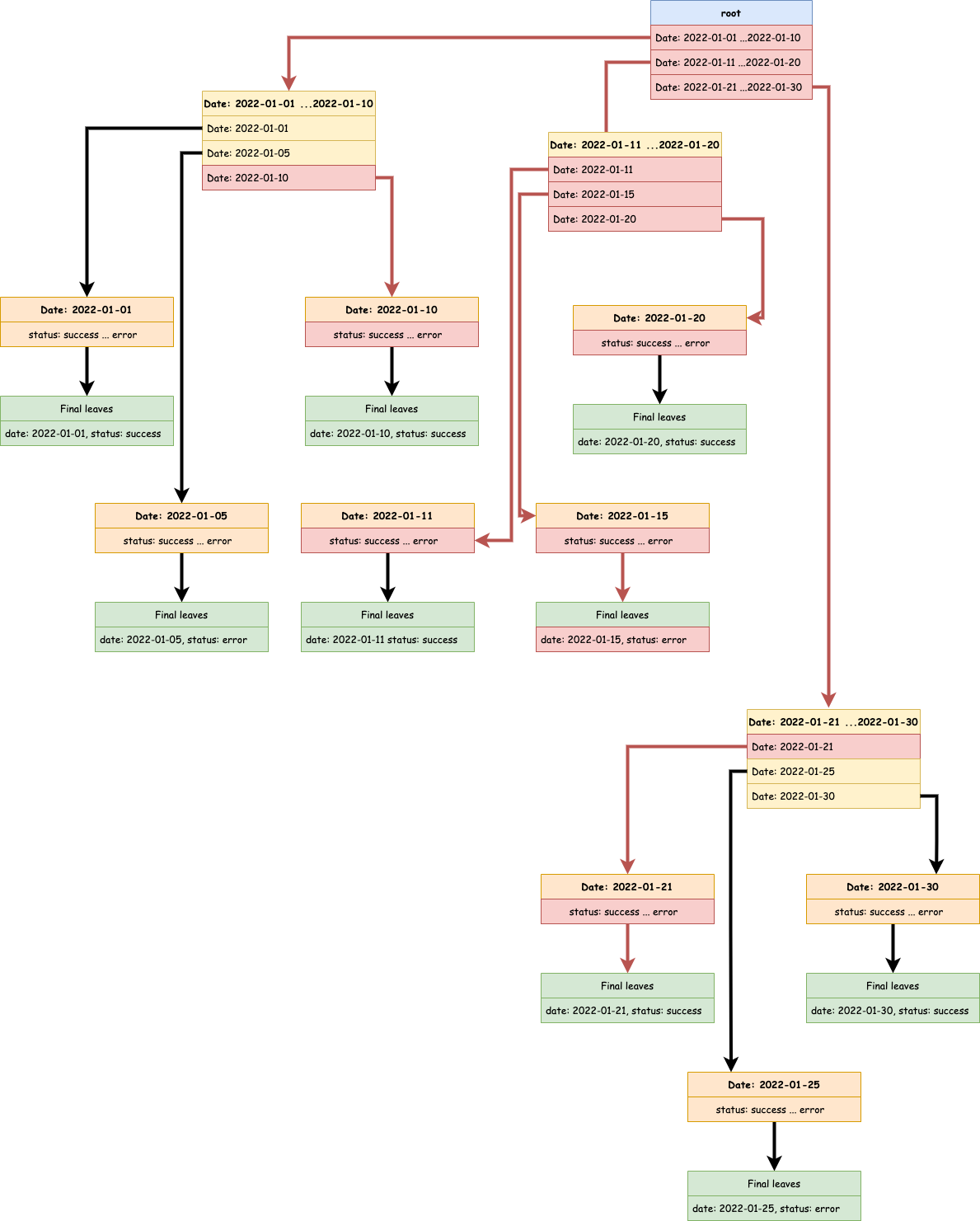
Pour finalement récupérer un seul enregistrement, nous avons un parcours extrêmement complexe et coûteux.
Si on valide par la pratique, en reprenant notre jeu de données de test, on va demander une plage de date correspondant à environ 500 000 runs (sur 10 millions de runs dans la table).
| Scénario | Temps d’exécution requête date | Temps d’exécution requête runs en error entre deux dates | Taille des index |
|---|---|---|---|
| Sans index | +/- 2s | +/- 2s | 0Mb |
| index date_status | +/- 2ms | +/- 310ms | 160Mb |
| index date | +/- 2ms | +/- 300ms | 120Mb |
| index status | +/- 2s | +/- 100ms | 45Mb |
On observe effectivement que notre index composé ne fait pas mieux qu’un index uniquement sur le champ date.
Il est important de noter que plus la fenêtre temporelle de requête est large, pire vont être les performances de cet index.
A l’inverse, plus la fenêtre est étroite meilleur sera l’index.
C’est donc un véritable camouflet pour le postulat de départ : un index composé sur A-B permet de requêter sur A de la même façon que un index sur A
On observe même une valeur étrange, la requête est plus rapide avec l’index status que date_status. Pourquoi ? Tout s’explique avec les cardinalités. Nous avons 10 millions de runs dont 1% en erreur. Soit 100 000 runs alors que dans le parcours via date_status nous allons au final **parcourir 500 000 runs.
Ce qui nous amène a une première grande idée générale, un index composé efficace est le plus souvent un index réfléchi pour une et une seule requête.
Autre première observation, un index composé occupe environ le même espace que les index uniques qui le compose. Ca semble logique si on repense à la structure de l’arbre.
Comment exploiter au mieux le composed index
A partir de là, nous allons réfléchir aux solutions d’indexation qui s’offrent à nous et essayer d’en tirer quelques règles.
Indexer chaque champ
Contre toute attente, cette solution, sans aucune subtilité est souvent une bonne approche.
CREATE INDEX "date" ON "runs" ("date");
CREATE INDEX "status" ON "runs" ("status");
SI nous reprenons l’exemple précédent, voici le résultat du bench.
| Scénario | Temps d’exécution requête date | Temps d’exécution requête runs en error entre deux dates | Taille des index |
|---|---|---|---|
| Sans index | +/- 2s | +/- 2s | 0Mb |
| index date_status | +/- 2ms | +/- 310ms | 160Mb |
| index date | +/- 2ms | +/- 300ms | 120Mb |
| index status | +/- 2s | +/- 100ms | 45Mb |
| index date + index status | +/- 2ms | +/- 300ms | 160Mb |
C’est encore un coup d’épée dans l’eau, on ne fait pas mieux que avec date uniquement et la taille des index a augmenté.
Inverser l’index composé
Plutôt que d’avoir un index sur date puis status, on va inverser et le créer sur status puis date.
CREATE INDEX "status_date" ON "runs" ("status", "date");
| Scénario | Temps d’exécution requête date | Temps d’exécution requête runs en error entre deux dates | Taille des index |
|---|---|---|---|
| Sans index | +/- 2s | +/- 2s | 0Mb |
| index date_status | +/- 2ms | +/- 310ms | 160Mb |
| index date | +/- 2ms | +/- 300ms | 120Mb |
| index status | +/- 2s | +/- 100ms | 45Mb |
| index date + index status | +/- 2ms | +/- 300ms | 160Mb |
| index status_date | +/- 2s | +/- 3ms | 120Mb |
Ca y est nous avons enfin trouvé un index qui fonctionne pour la deuxième requête. Mais nous y perdons sur la première requête.
C’est bien la preuve que l’ordre des colonnes d’un index composé est très important.
Si nous reprenons notre arbre, voici l’explication.
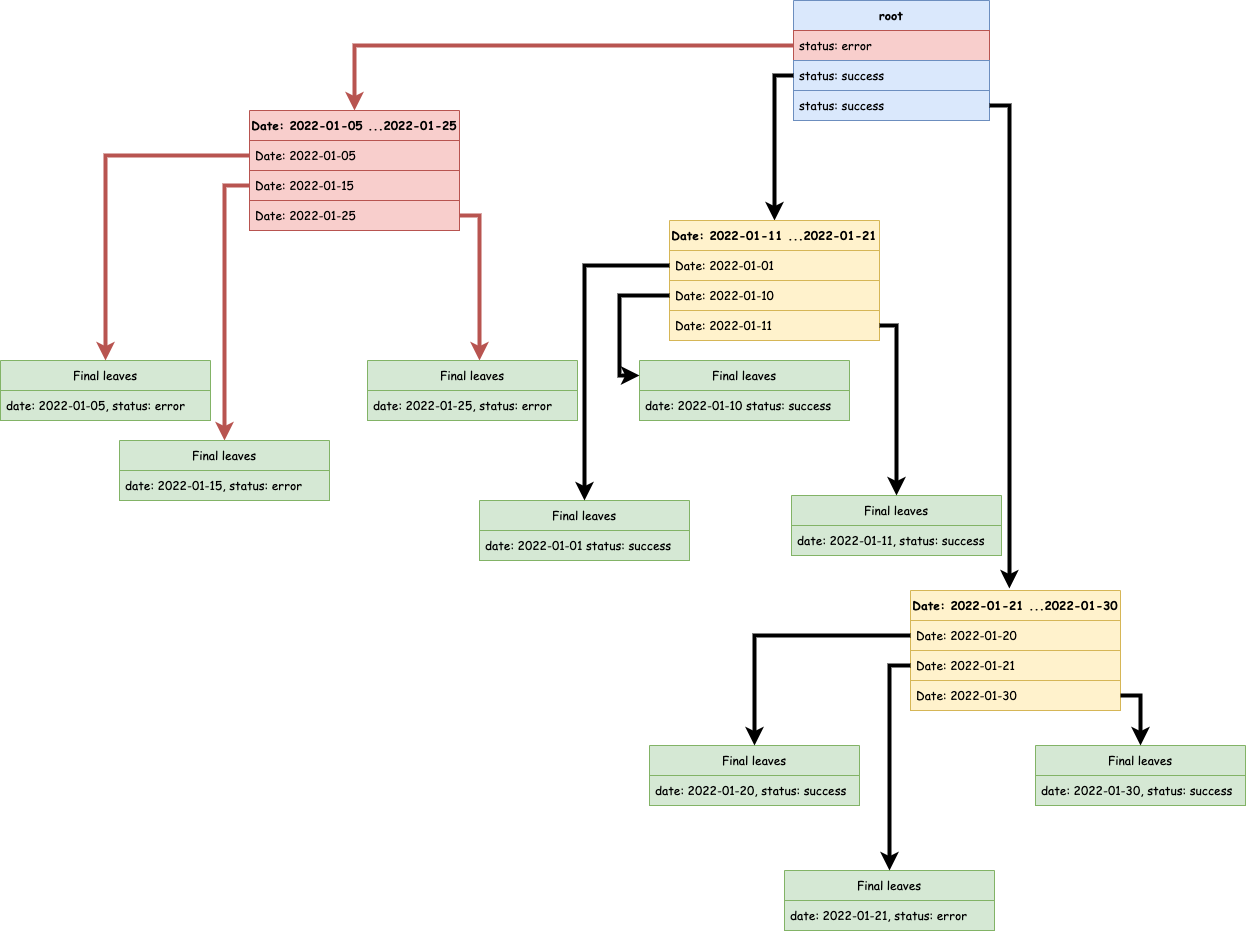
Visuellement on voit tout de suite pourquoi l’index marche bien.
Très peu de traits rouges, le chemin vers les feuilles est très direct.
Nous pouvons en tirer une nouvelle bonne pratique un index composé efficace commence par les colonnes dont les valeurs ont les plus faibles cardinalités : le moins de valeurs possibles.
Utiliser un index partiel
Certains SGDB comme MongoDB et PostgreSQL permettent de spécifier des conditions sur un index. Ca devient particulièrement intéressant à combiner avec un index composé qui sera tunné précisément pour une requête. Ca permettra de diminuer l’empreinte de l’index sur l’espace de stockage.
CREATE INDEX "partial_status_date"
ON "runs" ("status", "date")
WHERE status = "error";
Cet index va indexer runs de la même façon que l’index composé sur “status”, “date” mais
uniquement pour les enregistrements qui matchent la condition du WHERE.
| Scénario | Temps d’exécution requête date | Temps d’exécution requête runs en error entre deux dates | Taille des index |
|---|---|---|---|
| Sans index | +/- 2s | +/- 2s | 0Mb |
| index date_status | +/- 2ms | +/- 310ms | 160Mb |
| index date | +/- 2ms | +/- 300ms | 120Mb |
| index status | +/- 2s | +/- 100ms | 45Mb |
| index date + index status | +/- 2ms | +/- 300ms | 160Mb |
| index status_date | +/- 2s | +/- 3ms | 120Mb |
| index partial_status_date | +/- 2s | +/- 6ms | 1Mb |
C’est une vraie bonne nouvelle !
Pour 1Mb de stockage, nous avons un index qui va adresser très correctement la requête voulue.
En conclusion, les bonnes pratiques de la création d’index composé
Les leçons que nous avons tirées de notre exercice sont :
- l’ordre des colonnes d’un index composé est important
- un index composé vraiment efficace est souvent un index réfléchi pour une et une seule requête
- un bon index composé occupe environ le même espace que les index uniques qui le compose
- Dans le doute, on peut appliquer la règle suivante : un index composé efficace commence par les colonnes dont les valeurs ont les plus faibles cardinalités
- Les index partiels sont souvent un bon compromis, pour une taille qui peut être très réduite ils permettent de multiplier les index.
Maintenant j’espère que les index composés vous semblent beaucoup moins magiques.

La stratégie de benchmark
Pour valider nos futures hypothèses nous allons utiliser une table témoin contenant 10 millions de runs.
Chaque enregistrement a le format suivant :
| Colonne | Type | valeur |
|---|---|---|
| date | Date | date de type auto increment |
| status | Text | un enregistrement sur 100 en échec (⚠️ dans les graphes on a un échec sur 3 pour que ce soit plus compréhensible) |
Les benchmarks ont été fait sur mongodb, mais peuvent s’appliquer à PostgreSQL aussi.
Ressources
Repository github contenant le benchmark : https://github.com/jtassin/blog-post-composed-index-1