Monitoring de la complexité des models DBT
Bien que le sujet soit encore en chantier, voici les premières étapes que nous avons mises en place.
Suite à la mise en place de notre nouvelle architecture en médaillon
(voir l'article ici),
nous nous sommes rendu compte qu’il nous fallait maintenant creuser le sujet de la complexité de
notre codebase. Au moment où j’écris cet article nous avons presque 400 modèles et 70 sources de
données ! Un full-refresh (rafraichissement de tous les models sans prendre en compte
l’incrémental) prend environ 2h, un run classique environ 20min.
Bien que le sujet soit encore en chantier, voici les premières étapes que nous avons mises en place.
Complexité des lineages : DBT project evaluator
Notre première approche a été d’installer le package
DBT project evaluator : nous avions déjà un
linter de code, mais ici l’approche est plus structurelle et architecturale. Ce package propose
différentes “guide lines” qui permettent d’avoir un projet propre et maintenable, en signalant par
exemple les sources non utilisées, des modèles qui seraient à la fois parent et enfant d’un autre
modèle ou encore des mauvaises pratiques comme des join directement dans la couche bronze ou sur
les sources.
Dans un premier temps, nous avons ajouté ce package uniquement en local, les règles simples ont été corrigées, les cas que nous voulions garder tels quels ont été exclus via le fichier de seeds prévu à cet effet. Chaque règle à été revue par l’équipe, été activée ou non, paramétrée le cas échéant.
Corriger fct_rejoining_of_upstream_concepts était plus complexe. Nous avons listé les fichiers qui avaient cette alerte dans les exclusions, puis nous avons ajouté le package à la CI pour éviter que de nouveaux développements ne soulèvent d’autres alertes.
Depuis la mise en place de DBT project evaluator nous corrigeons petit à petit les modèles que nous
avons listé dans le fichier de seeds.
Exemple de simplification de lineage après correction d’une alerte fct_rejoining_of_upstream_concepts
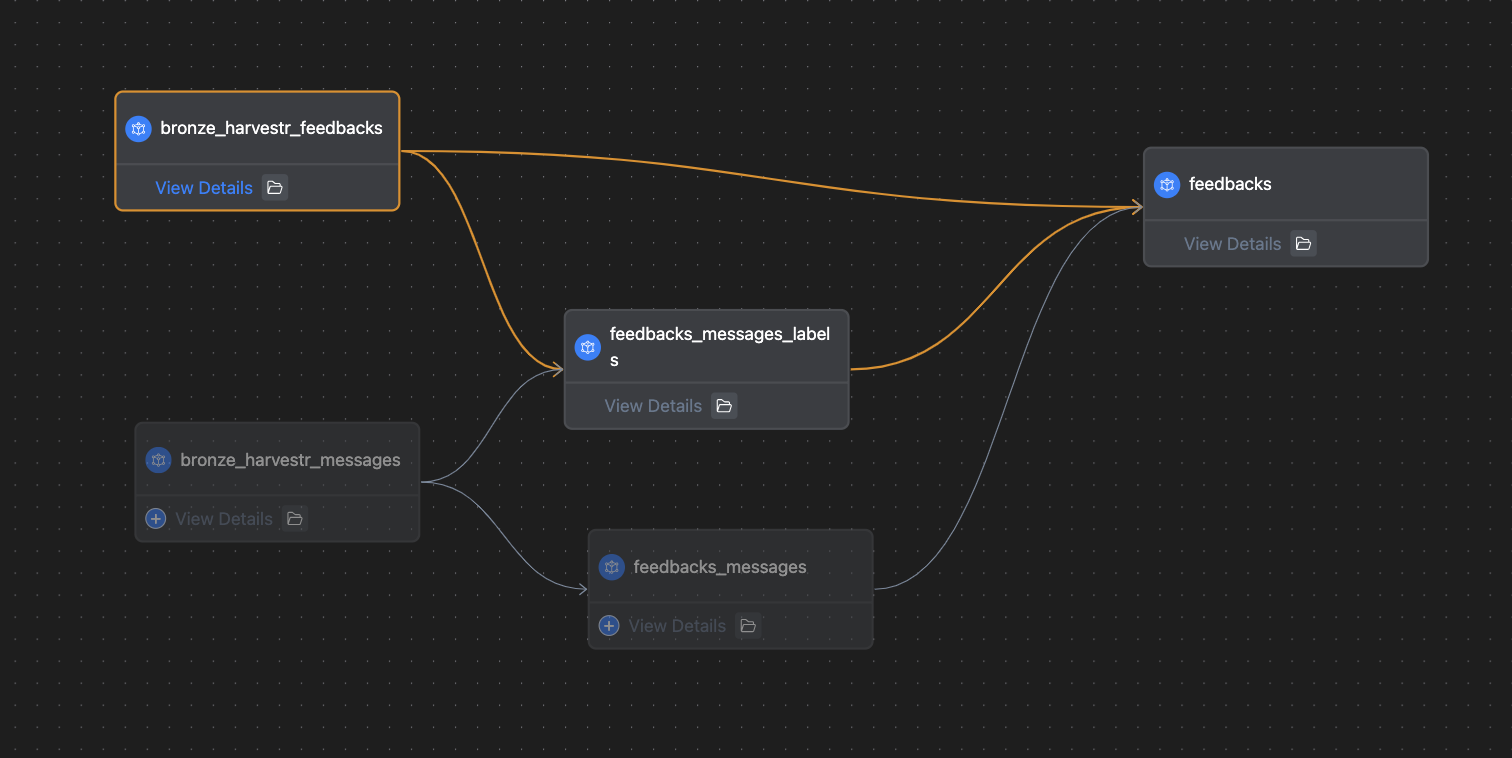
Avant refacto
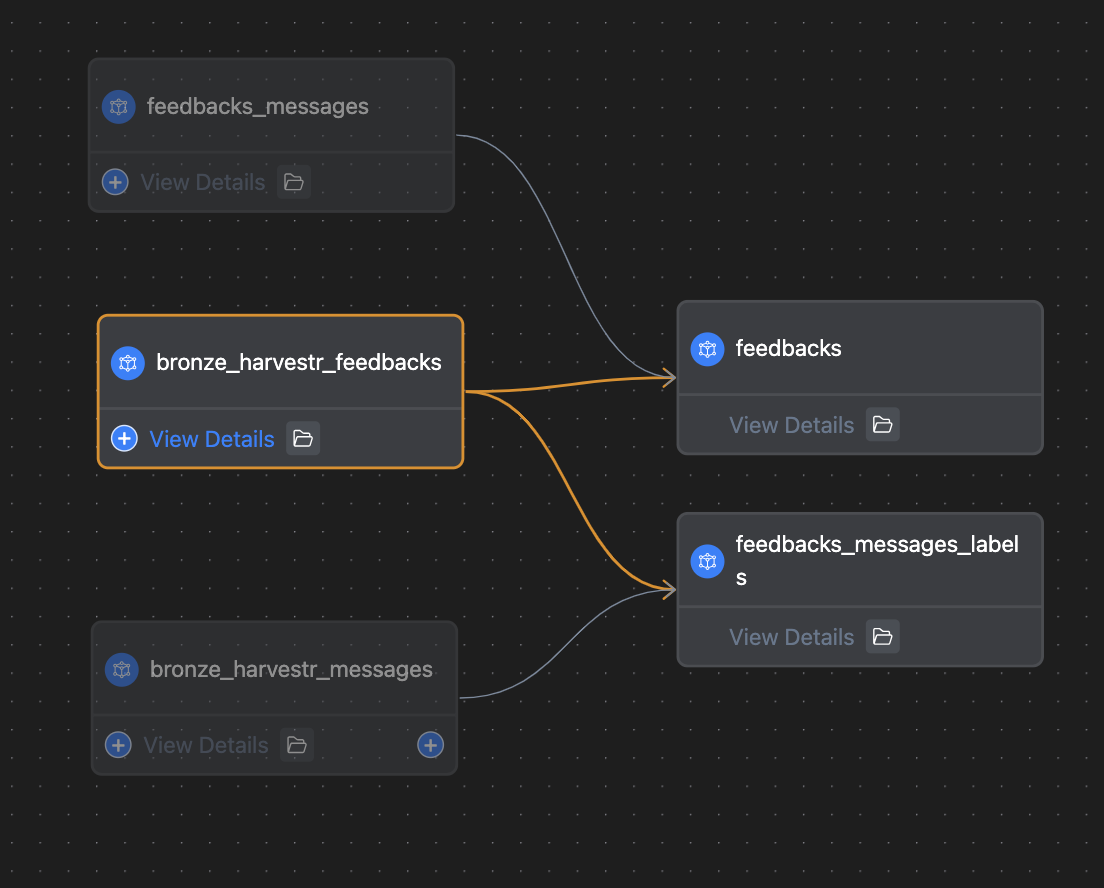
Après refacto
Complexité du code SQL : solution maison
Nous avons voulu partir sur un script Python, qui se base sur plusieurs indicateurs comme le nombre de colonne d’un modèle, l’occurence de mots clefs SQL et le nombre de modèles parents.
Nous avons défini une liste de mots clefs SQL et nous leur avons affecté une valeur en fonction de
leur complexité. Ainsi, un WHERE vaudra 1 point alors qu’un UNNEST ou un LAG vaudra 3 points,
et qu’un OR en vaudra 0,1. Nous sommes parti d’un premier mot clef auquel nous avons donné une
valeur arbitraire, puis pour chaque mot clef nous avons convenu ensemble d’une valeur plus ou moins
élevée en fonction des mots clefs déjà évalués. Nous n’avons bien évidement pas listés tous les mots
clefs disponibles en SQL, mais uniquement les plus récurrents dans notre projet, c’est à dire
environ une quinzaine.
Le résultat de ce script est ajouté à titre indicatif sur chaque description de PR via la CI, les résultats ne sont pour le moment pas sauvegardés pour un suivi plus précis.
Cet indicateur est pour le moment en phase de test, et nous permet notamment de valider certaines refactorisations dont le but est de réduire la complexité. Nous ajoutons encore des mots clefs dans notre liste quand un nouveau nous semble pertinent.
Exemple de résultat du script de calcul de la complexité
BEFORE public/care/care_working_days.sql nb_columns=8 sql=4.0 coupling=2 complexity=16
AFTER public/care/care_working_days.sql nb_columns=8 sql=1.0 coupling=2 complexity=12
BEFORE public/care/care_working_periods.sql nb_columns=2 sql=4.0 coupling=2 complexity=8
AFTER public/care/care_working_periods.sql nb_columns=2 sql=4.0 coupling=2 complexity=8
BEFORE public/sales/sales_cadence_hybride.sql nb_columns=10 sql=5.0 coupling=3 complexity=23
AFTER public/sales/sales_cadence_hybride.sql nb_columns=10 sql=5.0 coupling=3 complexity=23
BEFORE public/indies/working_days.sql nb_columns=6 sql=1.0 coupling=2 complexity=9
AFTER public/indies/working_days.sql nb_columns=6 sql=1.0 coupling=1 complexity=8
ADDED silver/care/silver_care_working_days.sql nb_columns=8 sql=3.0 coupling=2 complexity=15
-- nb models before=380 after=381 diff=1
-- global complexity before=15305 after=15314 diff=9
Et voici le code du script :
import argparse
import json
import re
from collections import Counter, defaultdict
TOKEN_COSTS = {
"AND": 0.1,
"COALESCE": 1,
"DISTINCT": 1,
"GREATEST": 1,
"GROUP": 1,
"JOIN": 1,
"LAG": 3,
"LEAD": 3,
"LEAST": 1,
"OR": 0.1,
"ORDER": 1,
"PARTITION": 3,
"SELECT": 1,
"UNNEST": 3,
"WHEN": 0.5,
"WHERE": 1,
};
def raw_sql_complexity(raw_sql):
raw_sql = re.sub(r"\W+", " ", raw_sql)
token_counts = Counter([token.upper() for token in raw_sql.split()])
return sum(token_counts.get(token, 0) * cost for token, cost in TOKEN_COSTS.items())
def analyze_manifest(manifest_file, coupling_factor=1.15, min_columns=10, max_columns=30, select=""):
with open(manifest_file) as fin:
manifest_data = json.load(fin)
data = {}
selected_models = {}
if select:
if select[0] == "+":
# If 'select' has a '+' sign, we need to find the direct dependencies of the selected model
for key, node in manifest_data["nodes"].items():
if select[1:] == node["name"]:
selected_models = set(node["depends_on"]["nodes"])
selected_models.add(node["unique_id"])
else:
# Otherwise, we just need to find the model with the given name
selected_models = {select}
for key, node in manifest_data["nodes"].items():
if node["package_name"] != "geppetto_dbt" or node["resource_type"] != "model":
continue
if (
select
and selected_models
and node["unique_id"] not in selected_models
and node["name"] not in selected_models
):
continue
node_data = {
"path": node["path"],
"nb_columns": len(node["columns"]),
"sql_complexity": raw_sql_complexity(node["raw_code"]),
"inputs": set(node["depends_on"]["nodes"]),
"outputs": set(),
}
data[key] = node_data
# compute outputs
for key, node in data.items():
for dep in node["inputs"]:
if dep in data:
data[dep]["outputs"].add(dep)
# compute coupling and global
for node in data.values():
node["coupling"] = len(node["inputs"]) + len(node["outputs"])
node["complexity"] = (node["sql_complexity"] + node["nb_columns"]) * coupling_factor ** node["coupling"]
return data
def print_manifest_complexity(data):
for node in sorted(data.values(), key=lambda node: node["complexity"]):
print(
f"{node['path']:50}\tnb_columns={node['nb_columns']}\tsql={node['sql_complexity']:.1f}\tcoupling={node['coupling']}\tcomplexity={round(node['complexity'])}"
)
print("---")
print(f"nb models => {len(data)}")
print(
f"global complexity{' of ' + args.select if args.select else ''} => {round(sum(node['complexity'] for node in data.values()))}"
)
def print_diff_complexity(data_from, data_to):
all_data = defaultdict(lambda: {"from": None, "to": None})
for node in data_from.values():
all_data[node["path"]]["from"] = node
for node in data_to.values():
all_data[node["path"]]["to"] = node
def print_node(prefix, node):
print(
f"{prefix}\t{node['path']:50}\tnb_columns={node['nb_columns']}\tsql={node['sql_complexity']:.1f}\tcoupling={node['coupling']}\tcomplexity={round(node['complexity'])}"
)
has_diff = False
for diff_nodes in all_data.values():
node_from, node_to = diff_nodes["from"], diff_nodes["to"]
if node_from == node_to:
continue
elif node_from is None:
print_node("ADDED", node_to)
elif node_to is None:
print_node("DELETED", node_from)
else:
print_node("BEFORE", node_from)
print_node("AFTER", node_to)
has_diff = True
if not has_diff:
print("No change on model DBT complexity")
else:
print("---")
print(f"nb models before={len(data_from)} after={len(data_to)} diff={len(data_to) - len(data_from)}")
global_before = round(sum(node["complexity"] for node in data_from.values()))
global_after = round(sum(node["complexity"] for node in data_to.values()))
print(f"global complexity before={global_before} after={global_after} diff={global_after - global_before}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Analyze DBT project manifest and produce a complexity report",
)
parser.add_argument("manifest")
parser.add_argument("--coupling-factor", type=float, default=1.15)
parser.add_argument("--min-columns", type=int, default=10)
parser.add_argument("--max-columns", type=int, default=30)
parser.add_argument("--select", type=str, default="")
parser.add_argument("--diff-from-manifest", default=None, help="Print diff with this manifest")
args = parser.parse_args()
if args.diff_from_manifest is not None:
data_from = analyze_manifest(
args.diff_from_manifest,
coupling_factor=args.coupling_factor,
min_columns=args.min_columns,
max_columns=args.max_columns,
)
data_to = analyze_manifest(
args.manifest,
coupling_factor=args.coupling_factor,
min_columns=args.min_columns,
max_columns=args.max_columns,
)
print_diff_complexity(data_from, data_to)
else:
data = analyze_manifest(
args.manifest,
coupling_factor=args.coupling_factor,
min_columns=args.min_columns,
max_columns=args.max_columns,
select=args.select,
)
print_manifest_complexity(data)