
Mise en place d’une archi médaillon sur la BI chez Indy
Nos données d'entreprises sont synchronisées sous format raw json dans une base PostgreSQL (Figure 1). Des jobs de tranformation des...
Pourquoi ?
Contexte
Nos données d'entreprises sont synchronisées sous format raw json dans une base PostgreSQL (Figure 1). Des jobs de tranformation des données (via DBT) transforment les données raw json en tables métiers qui sont ensuite exploitées dans notre outils de BI (Metabase).
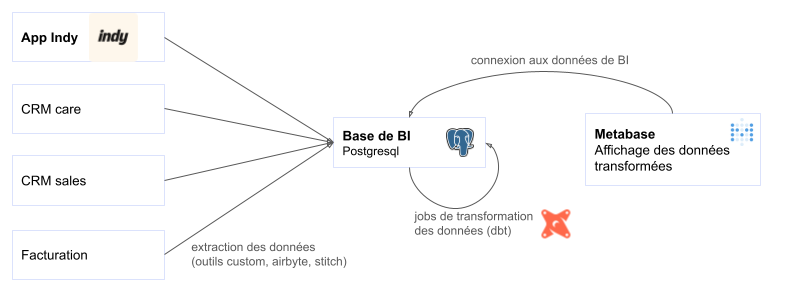
Figure 1: Schéma des échanges et accès aux données pour la BI
Problématique
On utilisait uniquement deux schémas pour traiter et restituer les données : staging et public
(Figure 2)
- Certaines données sources étaient directement requétées dans les modèles DBT finaux sans modèle intermédiaire de normalisation du json;
- Le schéma
stagingportait la double responsabilité de zone de test pour présenter des modèles en cours de développement et de normalisation des données JSON en format table; - Le nombre de sources et de données grossissant, l'organisation des modèles étaient de plus difficile à lire.
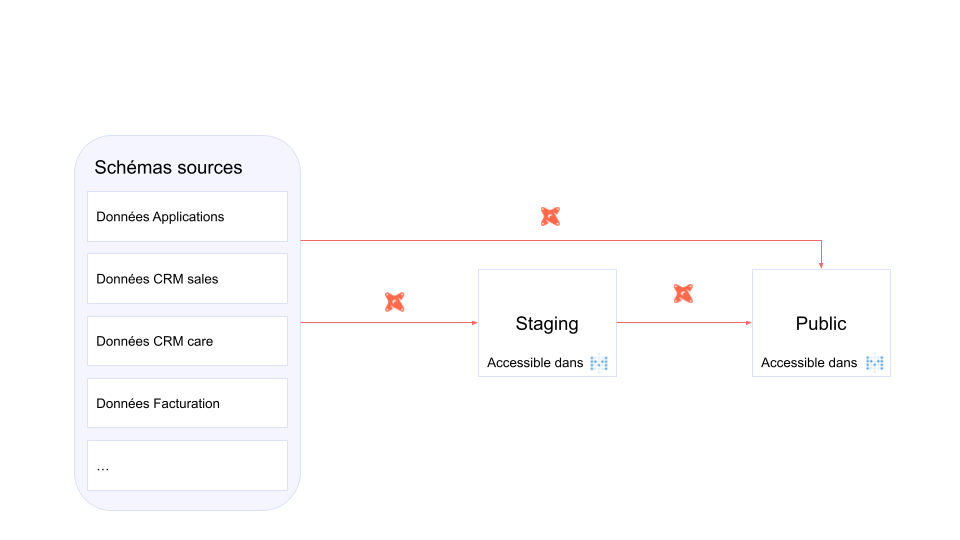
Figure 2: Ancienne architecture de nos données dans la base Postgresql, séparées en source, staging et gold (= public)
Nous avions besoin d'assainir et de clarifier le traitement des données, plus précisément:
- parser les données raw stockées en JSON pour les utiliser plus facilement;
- regrouper des données venant de différentes sources mais ayant la même définition métier;
- pouvoir faire des premiers calculs sur les données regroupées afin de faciliter les calculs dans les vues métier qui regrouperont plusieurs entités.
L'organisation en couches bronze -> silver -> gold proposée par databricks semblait répondre à
nos problématiques, nous l'avons adapté à l'organisation de nos modèles DBT.
Comment ?
Nous avons séparé l’organisation de nos modèles DBT en 3 couches de responsabilités différentes
bronze, silver et gold, avec une maturité des données croissante (Figure 3). La couche
staging ne garde que la responsabilité de rendre accessible temporairement des modèles en cours de
développement. Chaque couche est matérialisée par un schéma du même nom dans notre base de données.
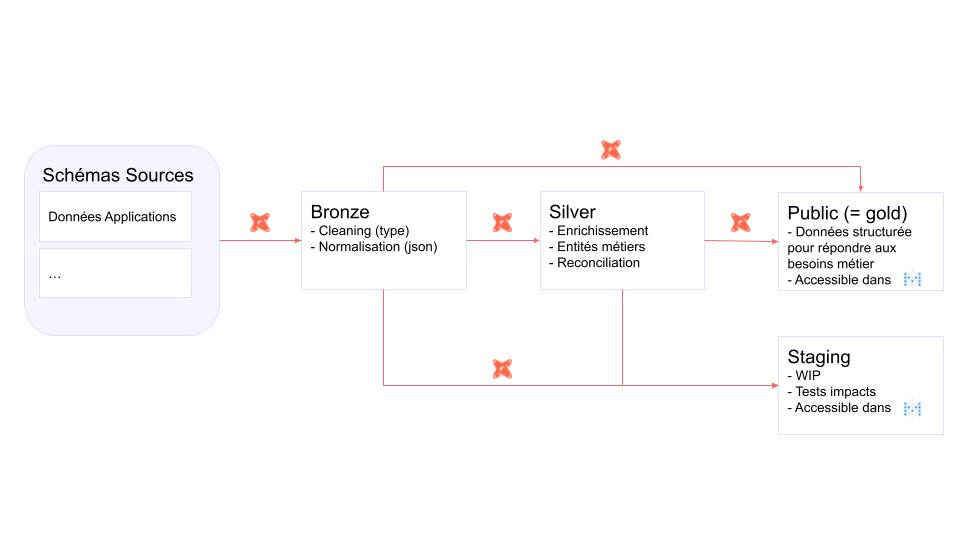
Figure 3: Architecture actuelle des données, les données sources ne sont requétées que par la couche bronze. Lles couches silver, gold et staging portent chacune des responsabilités différentes. Seules les couches Gold et Staging sont accessible dans l’outils de BI Metabase.
Les responsabilités et convention de nommage des différentes couches :
Bronze: Normalisation des données sources, les colonnes gardent un nom le plus proche de la source. Ils sont préfixé par “bronze_". Les models sont regroupés dans des dossiers en fonction de leur source de données. Les données ne sont pas accessible dans l’outils de BI (metabase)Silver: Enrichissement et filtrage des données, des colonnes peuvent être ajoutées, réconciliation des données, jointures entre tables autorisées. Les dossiers sont nommés par domaine métier si possible et par sources dans les autres cas. Les modèles sont prefixés par "silver_". Les données ne sont pas accessible dans l’outils de BI (metabase)Gold: Les données sont orientées business et organisées par domaine métier. Les modèles ne sont pas préfixés. Les données sont utilisées dans l’outils de BI.
Chronologie des étapes
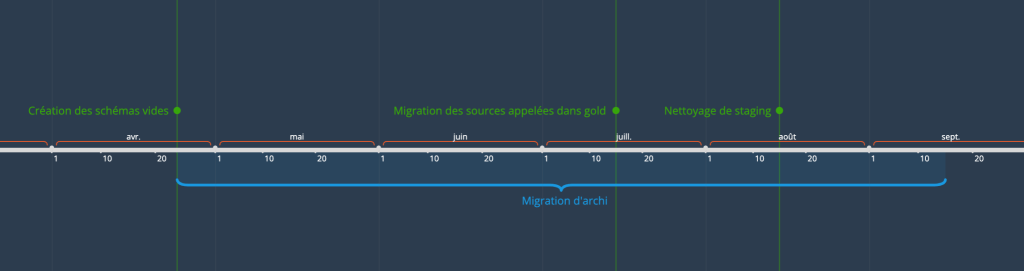
Début de la migration : 24 avril 2023 / Fin de la migration : 15 septembre 2023
La première étape a été de créer deux schéma vides pour bronze et silver. Nous avons choisi de
ne pas de juste renommer staging en silver pour avoir une meilleure visibilité des vues qu’il
nous restait à migrer. De plus, une fois vide, le schéma staging reprendrait sa responsabilité
unique de mettre à disposition des tables en cours de construction à destination de l’équipe ops,
consommatrice des données.
Nous avons migré les vues vers cette nouvelle architecture, au fur et à mesure des besoins et en parallèle du run.
Les noms des modèles bronze et silver ont été préfixés avec le nom du schéma, par exemple
bronze_pipedrive_activities car il n’était pas toujours logique de trouver un nom différent pour
bronze / silver / gold .
Nous nous sommes également autorisé à requêter directement bronze depuis gold quand la couche
silver n’avait pas lieu d’être, pour éviter de faire des models “passe-plats”.
Mi-juillet, notre objectif était de retirer toutes les sources appelées directement dans gold. La
liste a été faite dans notre gestionnaire de ticket, puis chaque membre de l’équipe a pris minimum
une tâche par semaine. Il n’en restait qu’une dizaine, en deux semaines nous avons pu valider cette
partie.
Mi-août, l’effort a été mis sur les modèles restants dans staging qui devait être migrés dans
bronze. Après cette étape, les modèles restants dans staging qui n’étaient ni des tests et ni
utilisés dans metabase ont été déplacés vers gold , les modèles encore en tests sont restés dans
staging et finalement les autres ont été supprimés.
Bénéfices et limites
- Clarté des données sources qui sont maintenant normalisées dans la couche bronze. Cela a beaucoup aidé lorsqu’il a fallu reconcilier des données historiques avec des données récentes après la mise à jour d’un connecteur d’une de nos sources.
- L’ajout d’indexes sur les tables
bronzeetsilver, contenant des gros volume de données, a permis d’accélérer le temps de création total de certains modèlesgold. - Les prefixes
bronze_etsilver_permettent de bien identifier à quel niveau sont les données requétées dans les modèles gold.
Et ensuite ?
Aujourd’hui les lineages sont bien plus hiérarchiques, ce qui simplifie la compréhension des
lineages d’une partie des models silver / gold.
Néanmoins après cette migration, nous pouvons compter plus de 360 models/fichiers SQL. Le code et
lineages de certains modèles centraux dans gold ne sont pas toujours simples, à cause de fallbacks
sur différentes sources, du nombre de colonnes qui augmente.
Cela nous a conduit à nous interroger sur la complexité de notre base de code et à réduire et corriger des mauvaises pratiques, avec par exemple l’utilisation du package dbt_project_evaluator.
Pour aller plus loin
- Architecture medallion proposée par databricks https://www.databricks.com/fr/glossary/medallion-architecture
- L’article
the-most-efficient-way-to-organize-dbt-models
présente des problématiques et un choix de structuration similaire. L'auteur a suivi le même
chemin que nous de
staging-martproposé par dbt àbase-intermediate-mart/core(assez équivalent à nos définitions debronze-silver-gold). - https://www.youtube.com/watch?v=9x5EBQk2P5Q