Application Events
Qu’entendons-nous par événement métier chez Indy ?
Introduction des événements métiers chez Indy
Tag : scalabilité, architecture
Authors : Koenig R. avec l’aide de la team Core
Termes employés
Qu’entendons-nous par événement métier chez Indy ? Dans le cadre d'Indy et de sa comptabilité je vais donner des exemples qui peuvent vous parler, histoire de bien illustrer la chose :
Nous aurons un événement métier lorsque par exemple un utilisateur...
- termine son onboarding
- s'abonne
- ajoute son compte bancaire
- clôture sa liasse fiscale
- ajoute une transaction
- change la catégorie d’une transaction
etc...
Lorsque ces événements arrivent, on veut pouvoir exécuter du code qui n’est pas relatif au cœur du produit. J’entends par là, par exemple, que lorsqu’un utilisateur ajoute une transaction, on exécute bien le code métier qui ajoute une transaction dans l’application : C’est le produit. Mais on veut aussi exécuter du code qui n’a rien à voir avec ce cœur de produit et ça peut être assez divers : Envoyer un email ou une notification, mettre à jour un CRM, envoyer une requête à un microservice.
Ce code lui est nécessaire au bon fonctionnement de l'entreprise, mais le produit et l’utilisateur, eux, s’en fichent. Ainsi il serait dommage que l’utilisateur final soit pénalisé par du code destiné aux équipes d’Indy. Que ce soit en termes d'erreur, bugs ou de délais à cause d'un élément exogène.
Exemples de problèmes “Avant”
Pour illustrer un peu plus loin les problèmes qui ont pu nous mener à cette réflexion, je propose de voir des exemples sur lesquels nous nous sommes cassés un peu les dents :
Exemples :
import serviceX from 'serviceX';
import serviceY from 'serviceY';
import CRM1 from 'CRM1';
function finalizeOnboarding(...) {
const user = await saveUser(); // do the interesting stuff for the client
await serviceX.initConfigurationServiceX();
await serviceY.initConfigurationServiceY();
// [...]
await serviceX.updateCRM1(); // That is our stuff
return user;
}
Les trois dernières fonctions sont indépendantes, mais elles doivent être exécutées lors de la finalisation de l'onboarding.
Le premier problème est qu'une erreur dans une de ces fonctions peut entraîner la non exécution des suivantes, qui pourtant ne sont pas liées (elles n'attendent pas le retour des précédentes) et laisser le code et la data dans un état incertain. Dans le pire des cas : On renvoie même une erreur à l’utilisateur qui est bloqué dans son onboarding.
Alors on peut répondre à ce problème en ajoutant des try catch et c'est ce que nous avons fait :
import serviceX from 'serviceX';
import serviceY from 'serviceY';
import CRM1 from 'CRM1';
function finalizeOnboarding(...) {
const businessResult = await myBusinessFunction();
try {
await initConfigurationServiceX();
} catch (error) {
// do something... maybe
}
try {
await initConfigurationServiceY();
} catch (error) {
// do something... maybe
}
try {
await updateCRM1();
} catch (error) {
// do something... maybe it depends of the CRM
}
return businessResult;
}
C'était un compromis simple et rapide, qui nous a permis de continuer un certains temps.
Ici nous n'avons plus le problème des erreurs mais nous avons encore des fonctions qui sont liées de
manière synchrone. Typiquement si une fonction prend beaucoup de temps, elle va différer l'exécution
des suivantes, ainsi que l'exécution de la fonction finalizeOnboarding de manière générale.
On pourrait éventuellement répondre à ce point en les wrappant aussi d'un setImmediate. Ce que
nous verrons dans la suite. (aussi possible de faire sans await avec un simple .catch)
En monitoring, cette fonction nous a montré qu'elle pouvait s'exécuter en 0.2s comme parfois 4s et
même plus rarement 40s, en fonction du temps de réponses des API externes... Car souvent nos outils
sont des SaaS externes ! Ce qui bien sûr peut entraîner un timeout pour le client. Ces événements
devenant plus fréquents, cette implémentation est de moins en moins acceptable. (problème
:performances)
Un autre problème est la charge mentale. Un autre développeur, s’il ne connaît pas l'historique, ou
s'il l'a oublié, peut assumer que ces fonctions ne sont pas indépendantes et que l'ordre doit être
respecté : Par exemple parce que chaque fonction va muter l'état en base de données et que les
autres s'attendent à ce nouvel état (ce qui est une mauvaise pratique, mais comment savoir quand on
ne connaît pas le code par cœur ?). Sans une inspection de chaque fonction c'est difficile de
savoir, la confiance s'en trouve réduite, et ça freine le développeur dans sa refonte éventuelle,
dans son ajout de feature etc... ( problèmes: perte de confiance, pauvre maintenabilité)
Je continue dans ma liste des problèmes : A un autre endroit de l'application nous avions des fonctions à exécuter lors d'une modification sur un modèle, c’était fait via un hook :
import updateCRM from "./crm.service.js";
async function postHook(user) {
try {
await updateCRM(user);
} catch (err) {
logError(err);
}
}
Cette fonction étant dépendante du service de CRM en question qui est un service de haut niveau et qui importe d'autres modules.
Ce qui a pour effet de coupler notre modèle de données à d'autres modèles et services d'autres modules, CRM1 dépendant de tous.
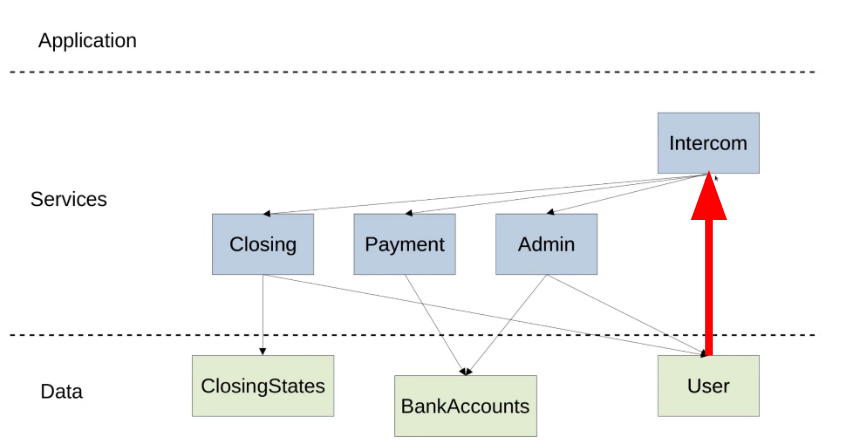 Dépendances entre les modules : Intercom
étant un CRM
Dépendances entre les modules : Intercom
étant un CRM
Ce qui entraîne des problèmes d'imports, des dépendances circulaires, des difficultés à comprendre et étendre le système.
(problèmes: couplages des services, violation d'architecture)
Solution
On veut pouvoir : Exécuter du code sans bloquer la requête initiale
Bien sûr le code métier qui doit être fait par la route et nécessaire à la réponse faite au client sera bloquant, mais le code indépendant qui doit être exécuté ne doit plus l'être pour la requête initiale, comme la mise à jour d'un CRM par exemple.
Alors pour répondre au problème du non bloquant nous pouvons utiliser setImmediate:
import serviceX from './serviceX';
import serviceY from './serviceY';
import CRM1 from './CRM1';
function finalizeOnboarding(...) {
const businessResult = await myBusinessFunction();
setImmediate(() =>
try {
await serviceX.initConfigurationServiceX();
} catch (error) {
// do something... maybe it depends of the CRM
}
));
setImmediate(() =>
try {
await serviceY.initConfigurationServiceY();
} catch (error) {
// do something... maybe
}
));
setImmediate(() =>
try {
await serviceX.updateCRM1();
} catch (error) {
// do something... maybe
}
));
return businessResult;
}
et
import updateIntercom from 'intercom.service.js';
async function postHook(user) {
setImmediate(() =>
try {
await updateIntercom(user);
} catch(err) {
LogError(err)
}
));
}
Cela peut résoudre le premier point (Toujours est-il que la lecture de la fonction ne s'améliore pas).
Mais nous avons toujours le problème des dépendances. Pour ça, on va vouloir :
⇒ Casser la dépendance et découpler notre code applicatif du code qui doit réagir. (Inversion of control)
Par exemple, on ne veut plus que le model user dépende du service Intercom qui est un CRM. Cela parait évident mais je me permets d'enfoncer le clou avec le OCP (Open Closed Principle) de SOLID comme quoi le code doit être ouvert à l'extension et fermé à la modification.
Typiquement si demain on ajoute un nouveau CRM, ou un nouveau module métier je ne veux pas avoir à modifier le code de User pour y insérer : "Importer le code du nouveau module, appeler la bonne fonction pour l'action désirée comme mettre à jour le CRM ou initialiser le module".
Mais on doit pouvoir ajouter un nouveau service, qui aura une fonction qu'il faut appeler, au bon moment, qui ne bloquera pas la fonction métier originelle, qui pourra être monitorée par ailleurs pour ceux que ça regarde sans polluer ceux qui s'occupent du métier. Le tout étant dans un fichier/dossier/repo différent qui peut être la responsabilité d'une autre équipe.
Pour avoir l'inversion of control il nous faut le pattern Observer.
(voir section JavaScript pour la suite)
class Subject {
observers = [];
attach(observer) {
this.observers.push(observer);
}
notify() {
this.observers.forEach((observer) => {
observer.update();
});
}
}
class Observer {
update() {
// Do what you have to do
}
}
Par exemple, car c'est plus clair avec des exemples, nous aurons ici User qui serait un subject
et les différents modules et/ou CRM des observers.
Comme Intercom observe le user et réagit à ses changements d'état, nous avons l'observer qui
importe le Subjet pour avoir accès à la fonction attach et s'attache.
Le rôle du sujet est juste de signaler son changement d'état via notify et la fonction update de l'Observer sera appelé :
// intercom.service.js
import User from "./user";
class intercom {
async update() {
// Build data and call API
}
}
User.attach(intercom);
Et dans User nous avons désormais :
async function postHook(user) {
setImmediate(() =>
try {
this.notify();
} catch(err) {
LogError(err)
}
));
}
L'import a disparu du fichier User ! 🎉 Nous avons donc un fichier haut niveau qui importe un fichier plus bas niveau (User ici) tout est rentré dans l’ordre.
Bon dans cette implémentation naïve, tout est synchrone, la gestion des erreurs n'est pas faite, on veut pouvoir avoir des noms d'événements différents pour un même sujet... Il reste du chemin à faire.
Heureusement la plupart des langages offrent de manière native des class pour implémenter ce
pattern et en Node nous avons EventEmitter.
https://nodejs.org/api/events.html
Pourquoi tant de focus sur ce découplage ?
En tant qu'architecte chez Indy, un de mes principaux driver aujourd'hui est de gérer une base de code modifiable par une équipe de plus de 30 développeurs, et de poser les fondations pour une équipe de 60 développeurs.
D'expérience, les problèmes de communications priment sur les problèmes techniques pour lesquels on trouve toujours une solution. C'est pourquoi découpler le code, et par extension les teams qui en sont responsables est un objectif très haut dans ma roadmap.
Typiquement, sur le code vu plus haut, la gestion du modèle user pourra être l'object d'une squad
A, pendant que la gestion du CRM1 pourra être la responsabilité d'une squad B etc...
Le code pouvant être protégé par le système de code owners (de Github ou GitLab), et les squads pouvant avoir des priorités différentes, je veux que chacune puisse avancer au maximum sans attendre le retour d'une autre.
C'est pourquoi ce découplage est si important à mes yeux.
Avec ce pattern, on peut avoir un code métier complètement découplé du code non-métier destiné à l’entreprise. De plus on peut avoir autant de listeners que l’on veut, ces derniers étant découplés entre eux aussi.
L'enjeu ici, c'est définir les interfaces entre les squads et comment je les sépare. Ici je réponds au fait que ce sont les Services externes qui importent User et qui réagissent dessus. Le code entre les squads est soumis aux ADRs (ensemble de règles et conventions que nous avons entre développeurs chez Indy) ce qui ne sera pas forcément le cas du code soumis à une seule squad.
Implémentation moins naïve
import EventEmitter from "events";
import _ from "lodash";
import { createLogger, newEventContext } from "../../logger.js";
import config from "../../config";
import {
getCheckAlreadyRegisteredListener,
isEventListenerEnabled,
} from "./applicationEvents.model";
const logger = createLogger({ namespace: "application-events" });
const eventsEnabledConfig = config.private.applicationEvents.events;
const listenersEnabledConfig = config.private.applicationEvents.listeners;
const eventListenersEnabledConfig = config.private.applicationEvents.eventListenerPairs;
export function createApplicationEvents() {
const eventEmitter = new EventEmitter();
eventEmitter.setMaxListeners(10);
eventEmitter.on("error", (err) => {
logger.error({ err }, "[ApplicationEvents] Internal event emitter error");
});
// Memoize to prevent log spam
const logEventWithoutListener = _.memoize(({ eventName }) => {
logger.info(
{ eventName },
"[ApplicationEvents] An event has been emited but no listeners are registered for this event",
);
});
return {
emit(eventName, payload) {
// Don’t trigger the event if it is disabled
if (!isEventListenerEnabled({ name: eventName, config: eventsEnabledConfig })) return;
const listenerCount = eventEmitter.listenerCount(eventName);
if (listenerCount === 0) {
logEventWithoutListener({ eventName });
}
return eventEmitter.emit(eventName, payload);
},
on(eventName, listenerName, cb) {
const eventListenerKey = `${eventName}-${listenerName}`;
// Don’t register the event if the listener is disabled
if (!isEventListenerEnabled({ name: listenerName, config: listenersEnabledConfig })) return;
// Don’t register the event if the pair event-listenner is disabled
if (!isEventListenerEnabled({ name: eventListenerKey, config: eventListenersEnabledConfig }))
return;
checkAlreadyRegisteredListener({ eventListenerKey });
eventEmitter.on(eventName, async (payload) => {
setImmediate(() =>
newEventContext({ eventName: eventListenerKey }, () => cb(payload, eventName)),
);
});
},
};
}
Quel type de payload dans les événements métiers ?
⇒ Payload minimal
Lorsqu'on émet un événement, on peut passer plus ou moins de data à cet évènement pour les listeners derrières.
Payload léger
Il s'agit de passer le minimum syndical d'informations pour que les listeners puissent fonctionner, ce qui a pour but d'alléger au maximum la fonction métier, typiquement on passe des arguments non objets, type String ou Number comme un ID :
async function updateUser({ userId, newFields }) {
await UserRepository.udpate({ userId, newFields }});
User.emit('updateUser', userId);
}
// Other file :
User.on('updateUser', (userId) => {
const user = UserRepository.findOne({ userId });
await updateCRM1(user);
})
// Other file :
User.on('updateUser', (userId) => {
const user = UserRepository.findOne({ userId });
await updateCRM2(user);
})
On pourra essayer de DRY (Don’t repeat yourself) par la suite, mais sans compromettre le driver numéro 1 de découplage.
Payload lourd
Une autre approche est de préparer le payload pour les listeners, ce qui peut éviter de recopier du code, d'alléger les appels à la base de données :
async function updateUser({ userId, newFields }) {
await userRepository.udpate({ userId, newFields }});
const user = userRepository.findOne({ userId });
userEvents.emit('updateUser', user);
}
// Other file :
userEvents.on('updateUser', (user) => {
await updateCRM1(user);
})
// Other file :
userEvents.on('updateUser', (user) => {
await updateCRM2(user);
})
Ici on introduit donc une fonction non nécessaire au métier dans la première fonction updateUser, le contrat entre l'évènement et ces listeners est plus fort. Donc la première team doit avoir une meilleure connaissance des listeners potentiellement gérés par d'autres personnes.
Le compromis ici est une interface et une contrainte plus forte entre les teams composées d'humains pour une optimisation du code.
Conclusion
Il se trouve que la plupart du temps l'optimisation de code de la solution 2 est négligeable comparé au coût de communication humain, et c'est pourquoi ce n'est pas notre priorité et que cette solution n'est retenue que dans les cas prouvés comme étant problématiques.
Les deux peuvent fonctionner, mais étant donné que notre driver architectural est le découplage. Nous allons retenir la solution 1 du payload léger, quitte à gérer les côtés négatifs dans un second temps.
On utilise un pattern Observer basé sur le EventEmitter de Node pour découpler le code et les teams aux maximum. En ce qui concerne les évènements, le payload sera minimal et les listeners seront aussi découpés dans des fichiers différents.