Introduction du bus d'entreprise chez Indy
Récemment, chez Indy nous avons pris la décision d’ajouter un bus d’entreprise à la stack technique.
Récemment, chez Indy nous avons pris la décision d'ajouter un bus d'entreprise à la stack technique.
Nous allons passer en revue certaines des raisons qui nous ont poussé à faire ce choix.
Contexte : L'équipe tech et product est désormais composée de 39 personnes dont 32 développeurs.
Cette décision n'est pas forcément facile à prendre car elle introduit de la complexité nouvelle dans la stack technique. Ainsi que des techniques et des pratiques pour lesquelles la plupart des développeurs de l'équipe ne sont pas encore familiers.
Néanmoins après avoir réfléchi à la question et à la connaissance des personnalités qui forment l'équipe, je pense que c'est la voie de la scalabilité pour la boîte. Ce ne sera peut-être pas votre cas, donc je partage notre prise de décision et je ferai une suite d'articles sur l'adoption de cette pratique après quelques mois puis après un an.
Fils conducteurs
Pour expliquer comment l'architecture évolue, on peut citer nos fils conducteurs, et résumer la situation actuelle.
Nous avons un monolithe principal (Indy) sur lequel se trouvent les règles métiers, qui sert de backend à notre frontend et qui synchronise aussi un petit régiment d'outils externes. Ces outils ne sont pas liés à notre produit principal mais participent au bon fonctionnement de l'entreprise, notamment la synchronisation de nos différents CRM.
Historique

L'app a commencé simplement avec une connection Indy <-> Intercom. Intercom est l'outil utilisé par nos care pour faire la relation client. La première intégration demandée a été de remonter des informations du client sur Intercom comme : L'utilisateur est-il abonné ? A-t-il terminé sa clôture, dans quel régime fiscal se trouve-t-il ?
Puis nous avons eu une intégration Gsheet avec l'équipe marketing qui sortait des données d'Intercom à des fins d'analyses. Synchro au début manuelle qui est passé automatique.
Un peu plus tard, nous avons intégré le CRM de l'équipe Sales : pipedrive, ici aussi nous avons du remonter des informations du produit vers Pipedrive pour simplifier le travail des Sales en automatisant certaines actions sur pipedrive. Mais ici la relation est à double sens car nous devions récupérer des informations sur le commercial pour l'équipe marketing, ça remontait alors dans l'application pour aller dans Intercom pour aller ensuite dans GSheet (!).
/!\ Premier warning d'architecture ici : L'app Indy servait d'intermédiaire pour synchroniser pipedrive et notre BI de l'époque, code qui ne servait pas du tout l'intention originelle de l'app qui était de servir le client, c'était du code d'entreprise pur.
Puis nous avons ajouté Metabase qui aggrège les données des différents CRM ainsi que les données de l'application dans un outil qui sert à faire de la visualisation de données et de la BI.
Avec la croissance, on a continué à empiler les intégrations : Ringover pour des besoins sales, puis Trello pour de l'automatisation produit.
Nous avons continué avec des app internes qui manipulent l'API de CRM pour des besoins internes (autour de l'affectation d'Intercom), des intégrations entre nos CRM : Intercom et Pipedrive car des données de l'un étaient nécessaires dans l'autre.
Et le dernier ajout Slack qui s'intègre avec quasiment tous les autres services pour avoir nos infos dans notre outil de communication.

Le schéma devient vite complexe et il devient difficile pour un développeur, même ancien, de comprendre le flux de données et d'expliquer tout ce qu'il se passe sur notre système d'information.
Et ce schéma ne montre pas toute l'intégration de monitoring de l'application et des intégrations ! Ce n'était pas très gênant au début, mais cette complexité a conduit à des régressions.
Un fil conducteur sera alors : Le besoin d'être en mesure d'expliquer le sens des flux de données.
- Avoir une architecture plus explicite et systématique au niveau des synchros
- Que le sens de circulation des données soit plus explicite et systématique aussi
Un autre fil conducteur sera alors : Être en capacité de facilement rajouter une synchro sur le SI existant sans modifier le produit comptable et les autres services
Typiquement si demain on ajoute un nouveau CRM, il doit pouvoir écouter les évènements existants, faire sa propre synchro et en cas de crash, le faire sans impacter les autres services. En particulier le produit où se trouvent les clients.
Exemple d'échec suite à cet état :
Certaines API de nos CRM nous imposent un rate limit, ce qui n'est pas problématique au début mais avec la croissance de la boite on vient toucher ce rate limit inévitablement et une fois atteint, la plupart de nos requêtes échouent et notre synchronisation est perdue. C'est arrivé et le début du débug fut long et fastidieux car nous avions plein d'intégrations avec ce CRM, chacune plus ou moins bien monitorée. Il était alors difficile de trouver l'intégration qui posait problème et qui explosait le rate limit :
- Était-ce notre application principale ?
- Était-ce les ZAP (de Zapier) mis en place ?
- Était-ce son intégration avec un autre CRM ?
- Était-ce les jobs journaliers ? etc...
Une fois trouvé, comment respecter ce rate limit ? Comment le répartir sur les différentes intégrations ? Alors qu'elles n'ont pas la même criticité, qu'elles ne sont pas actives au même moment dans la journée, est-ce qu'il faut mettre en place une pile etc...
Nous avons perdu quelques semaines à résoudre ce point-là.
Volonté de changer
Ces problématiques sont assez classiques dans l'industrie et il existe beaucoup de littérature sur le sujet. Après nous être renseigné, nous avons décidé d'agir et de nous aligner sur ce qui se fait de manière générale sans chercher à être trop original.
Avec la croissance de la base de code et de l'équipe, nos drivers architecturaux (et humains) sont dorénavant :
- Découplage et autonomie des squads
- Pas d'erreur sur le produit principal
- Garder la volonté d'extension rapide de notre produit et SI
=> Il faut découpler ce qui peut l'être quitte à échanger un peu de complexité et introduire de nouvelles technologies. Les synchros propres à une squad et qui ne font pas partie du produit comptable sont des bons candidats.
Alléger notre codebase principale
Pourquoi sortir du code ? Retirer du code sans impacter nos fonctionnalités a toujours l'avantage de le rendre plus simple avec une interface exposée aux bugs plus faible. Il en va de même pour les dépendances, car la plupart des synchros viennent avec leur SDK et dépendances. L'envie de sortir le code de ces synchros, qui pèse dans la codebase du produit principal, s'est fait ressentir suite à des expériences parfois douloureuses sur les problématiques citées plus haut. Pour alléger le code du dépôt principal et du monolithe, ainsi qu'alléger ses dépendances, nous avons décidé de sortir le code qui n'était pas vital à notre métier : la compta.
Ceci permet d'avoir des équipes qui travaillent sur des dépôts différents pour du code qui a un but et une criticité complètement différentes, les laissant faire leur choix d'architecture, de CI et de process.
Je voulais aussi un découplage maximal, c'est pourquoi la solution d'appeler des services directement en HTTP ne me plaisait pas. Le pattern pub/sub est tout indiqué ici et est largement discuté dans la littérature, ce qui nous a amené assez rapidement sur cette proposition :
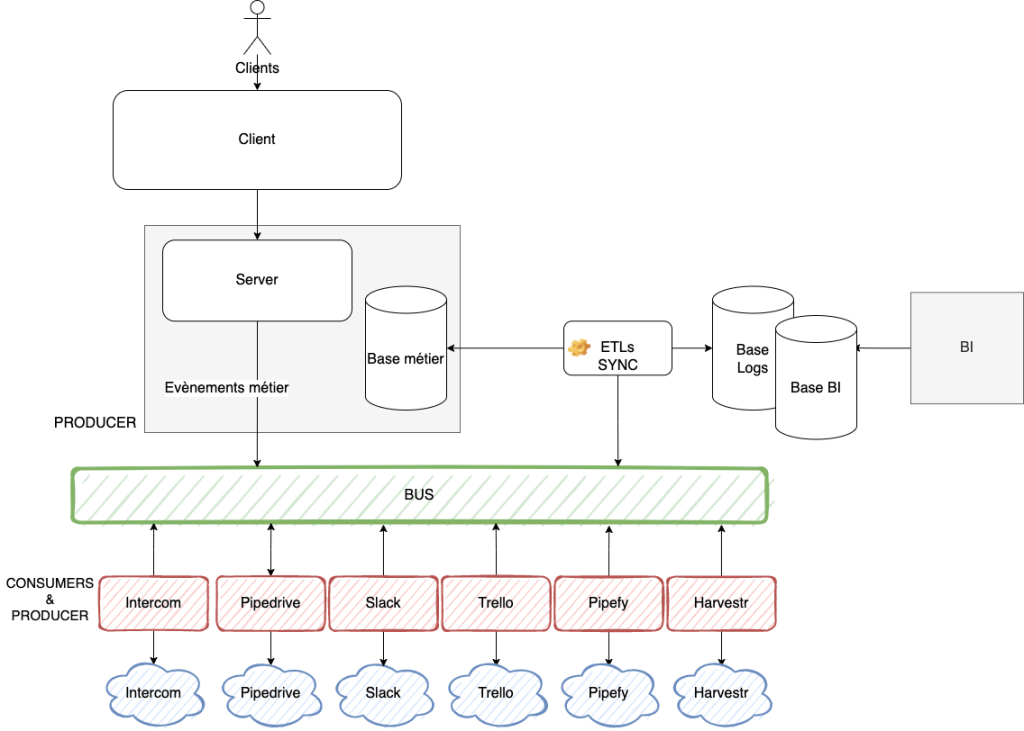
Tous les services ne sont pas représentés...
Le BUS fait office de SPOF (single point of failure), mais si le BUS tombe il n'y a pas d'impact sur le service pour les clients finaux.
Impacts sur le respect de SOLID
Le principe SRP (Single Responsibility Principle) est mieux respecté, il est plus facile de faire évoluer chaque petit module. Si l'API d'intercom change, on change le service en question et pas l'application de comptabilité, de même pour les autres services cloud.
Le principe OCP (Open/Closed Principle) est mieux respecté aussi. Si demain on veut ajouter un service, on peut le rajouter comme consumer du BUS sans toucher au reste du SI.
Gestion de la donnée nécessaire aux services externes
Une question se pose alors : comment envoyer sur le bus la donnée métier nécessaire aux applications de synchronisation de nos CRM ? Typiquement, lors d'un event user/subscribe par exemple, le nom de l'event et l'ID de l'utilisateur en soit ne suffisent pas. Le service pipedrive ou Intercom qui écoute sur le bus va vouloir que de la donnée soit attachée à l'évènement. Il existe alors trois solutions :
- Base de données partagée
- en PULL : les services appellent le produit principal à travers le réseaux
- en PUSH : le produit envoie la donnée sur le bus
1. Shared database :
Très rapidement écarté car cela ne sert à rien de découpler le code s'il reste couplé par le schéma de base de données. Ce modèle est trop fragile et bug-prone.
2. PULL Le service va chercher l'information par API :
Dans ce modèle, on essaye de garder le produit principal le plus simple possible en envoyant un évènement technique sans données métiers (uniquement des IDs). C'est au CRM en question de savoir quelles données il désire et d'aller les récupérer en interrogeant, par exemple, une simple API CRUD qui expose lesdites données.
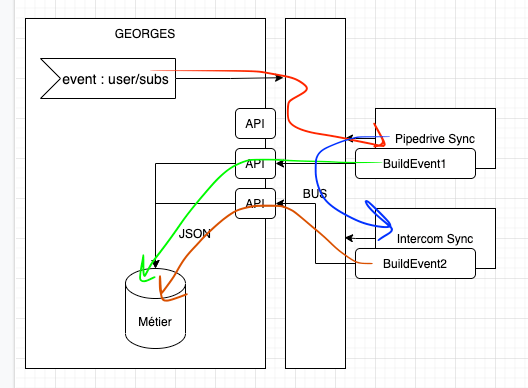
Avantages :
Le code de l'émetteur de l'event reste simple. On ne fait pas apparaître une
fonction buildEvent qui va aggréger des données qui, de première abord, n'ont rien à voir avec le
cas d'utilisation car c'est une spécifité de l'app de sync d'un CRM.
Désavantages :
Nous avons des routes qui sont potentiellement utilisées par des clients (l'interface) ou des apps internes. Il faut pouvoir les monitorer pour savoir si elles sont toujours utilisées ou non. Beaucoup de données transitent par le réseau donc il y a plus de risques d'erreur.
3. PUSH La data est formatté par Georges puis accroché à l'évènement
Ici la donnée est formattée dans l'émetteur directement puis attachée à l'event pour être envoyée sur le bus. Les modules n'ont pas à aller interroger l'émetteur pour récupérer des données supplémentaires.
L'enjeu ici est de ne pas polluer le cas d'utilisation d'une route métier avec l'agrégation de donnée qui serait un enjeu non fonctionnel, juste une spécificité de nos outils de sync.
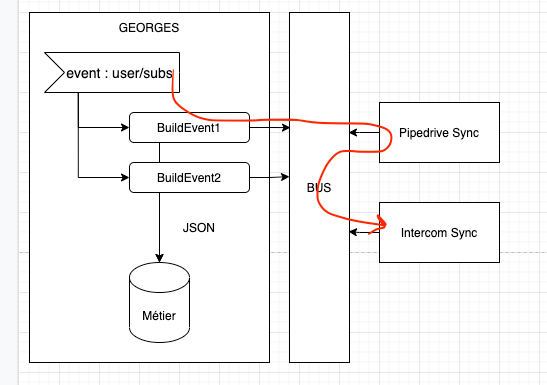
Avantages :
Possible de retrouver un cas d'utilisation simple débarassé des fonctions buildEvent (qui ne seront pas dans le même fichier).
On évite les appels de nos app vers Georges et les appels API qui partent dans tous les sens et qui sont dur à monitorer.
Désavantages :
Un peu plus de discipline dans le code de l'émetteur . On veut éviter que la fonction
de buildEvent, celle qui va aggréger des données métiers nécessaires à nos outils mais non
nécessaires au cas d'utilisation soit dans la route de ce dernier. Ceci peut être accompli avec des
évènements internes et un pattern Observer (voir futur billet de blog).
Conclusion
Je peux avoir des squads spécialisées sur le produit comptable qui n'ont pas connaissance des outils internes de la boîte !
Je peux avoir des squads spécialisées sur la maintenance de nos outils internes sans connaissance sur le produit comptable au-delà des données qui les intéressent (celle qui transitent sur le BUS).
L'enjeu, ici, est désormais de définir et respecter un contrat de données qui va passer sur le BUS. Cela peut être le rôle du CTO (qui est inter-squads), d'une personne de l'équipe data, d'un OPS. Le rôle étant de faire respecter ce contrat et vérifier la cohérence des données qui passent sur le BUS, (c'est-à-dire donner la spécification des buildEvents).